


July 8 • 40 min read
The Architect's Guide to Production Vector Search with Vertex AI and Cloud Run
Building smart AI apps with semantic search or RAG is accessible, but making them fast, scalable, and cost-effective is the real challenge. This Google Cloud guide helps architects and engineers achieve that. It explores Vertex AI's embedding models, such as gemini-embedding-001, demonstrating how model choice affects performance and cost. The guide also covers RAG and semantic search patterns, emphasizing the optimization of embeddings for specific tasks. You'll learn about efficient vector similarity search using tools like Faiss and ScaNN, and gain a blueprint for deploying workloads on Google Cloud Run, along with best practices for minimizing latency. A FastAPI application example provides a complete, production-ready solution.
1. The Landscape of Google Cloud Vertex AI Embedding Models
The efficacy of modern machine learning systems, particularly those involving natural language processing and multimodal understanding, is increasingly dependent on the quality and characteristics of their underlying vector embeddings. These numerical representations, which translate complex data such as text, images, and video into high-dimensional vectors, form the foundation for tasks ranging from semantic search to retrieval-augmented generation (RAG). [1] Google Cloud's Vertex AI platform provides a sophisticated suite of embedding models, each with distinct specifications, performance profiles, and cost implications. A thorough understanding of this landscape is paramount for architects and engineers designing scalable, efficient, and effective AI applications. This analysis moves beyond a simple enumeration of features to provide a comparative framework for strategic model selection, examining the critical trade-offs between performance, dimensionality, cost, and long-term viability.
1.1 A Comparative Analysis of Text Embedding Models
Vertex AI's text embedding models have evolved, reflecting a broader industry trend towards more powerful, generalist models. This evolution presents both opportunities for enhanced performance and challenges for maintaining systems built on older-generation models.
The Gemini Family (gemini-embedding-001)
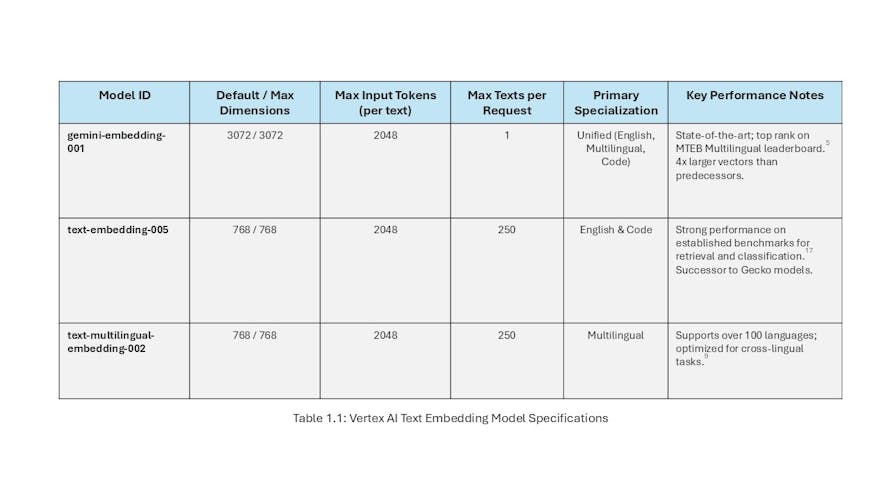
The gemini-embedding-001 model represents Google's current state-of-the-art offering for text embeddings. It is explicitly positioned as a unified model designed to surpass the performance of its predecessors across their respective specializations, including English, multilingual, and code-related tasks. [4] This model has demonstrated top-tier performance on industry-standard benchmarks, such as the Massive Text Embedding Benchmark (MTEB) Multilingual leaderboard, often achieving superior results out of the box without requiring extensive, task-specific fine-tuning.[5]
From a technical standpoint, gemini-embedding-001 generates highly expressive, dense vectors with a default and maximum dimensionality of 3072. [7] This high dimensionality is a key factor in its performance, allowing it to capture more nuanced semantic relationships within the data. However, this comes with a significant architectural trade-off. A 3072-dimensional vector consumes four times the storage and requires substantially more computation for distance calculations compared to the 768-dimensional vectors of previous models. [8] This directly impacts the cost and latency of downstream systems, such as vector databases and search services. Architects must therefore weigh the model's superior semantic capabilities against these tangible system-wide costs.
The model accepts a maximum input of 2048 tokens per text snippet. [4] A notable operational constraint is the API limitation: gemini-embedding-001 supports only a single input text per API request, in contrast to older models that allowed for batching multiple texts in a single call. [4] This necessitates a different approach to application logic, potentially requiring more frequent, smaller API calls when processing large volumes of documents.
The "Gecko" Family and its Successors (text-embedding-005, text-multilingual-embedding-002)
Prior to the ascendancy of the Gemini family, Vertex AI offered a suite of powerful, specialized models. While gemini-embedding-001 is the recommended choice for most new projects, these models remain relevant for existing deployments and specific use cases where their characteristics may be advantageous.
- text-embedding-005: This model, a successor to the original textembedding-gecko series, is specialized for English-language and source code embedding tasks.4 It generates vectors with a maximum dimensionality of 768 and shares the 2048-token input limit.4 Its lower dimensionality makes it a more cost-effective option for storage and computation, representing a viable choice for applications where the absolute highest semantic fidelity is not required or where budget constraints are paramount.
- text-multilingual-embedding-002: As its name implies, this model is optimized for multilingual applications, supporting over 100 languages, including widely used ones such as Spanish, French, Chinese, German, and Arabic.7 It produces vectors with the same 768-dimension, 2048-token specifications as its English-focused counterpart.4 While Google does not publish an exhaustive list of supported languages, community and third-party testing confirm its broad utility for global applications. [12]
A crucial architectural consideration is the clear trend of model consolidation. The introduction of gemini-embedding-001 as a unified model that outperforms its specialized predecessors suggests a strategic direction away from maintaining multiple, task-specific models. This pattern, observed with the potential discontinuation of the Gecko models for services like RAG Engine [14], implies that while older models are currently functional, they carry a higher risk of future deprecation. For new systems, standardizing on the Gemini family is the most forward-looking architectural decision. For engineers maintaining systems built on text-embedding-005 or text-multilingual-embedding-002, developing a migration strategy to gemini-embedding-001 should be a long-term consideration to leverage performance gains and mitigate future support risks.
Legacy Context (textembedding-gecko@*)
The models identified with the gecko suffix (e.g., textembedding-gecko@001, textembedding-gecko@003) represent the foundational technology upon which the newer text-embedding-* models were built. [15] They established the 768-dimensional output standard for their generation. While largely superseded, they provide important historical context and may still be present in older codebases and tutorials. [3] Awareness of their potential deprecation is critical for anyone working with Vertex AI RAG Engine, as a model discontinuation would necessitate a full re-indexing of the RAG corpus with a supported model. [14]
1.2 An Examination of Multimodal Embedding Models
Beyond text, Vertex AI offers powerful models that can create a shared semantic vector space for multiple data types, enabling novel cross-modal applications. [2]
The Primary Model (multimodalembedding@001)
The multimodalembedding@001 model is the workhorse for generating joint embeddings from text, image, and video inputs. [20] Its defining feature is the creation of a unified semantic space where vectors from different modalities can be directly compared. This means, for instance, that the embedding for the text "a picture of a cat" will be located near the embedding for an actual image of a cat, enabling powerful use cases like text-to-image search, image-to-video retrieval, and multimodal classification. [22]
However, this power comes with significant and specific limitations that architects must design around:
- Dimensionality: The model produces a default 1408-dimensional vector for all modalities. For text and image inputs, this can be optionally reduced to 512, 256, or 128 dimensions. This feature is a critical lever for trading model accuracy against storage costs and retrieval latency. [21]
- Input Constraints: The model's capacity for input is strictly limited. Text input is limited to 32 tokens and is restricted to English only. Images are limited to 20MB and are automatically resized to a 512x512 pixel resolution internally, meaning that providing higher-resolution images yields no benefit. For video, while there is no limit on the source file size from Cloud Storage, the model can only analyze up to two minutes of content at a time. Critically, any audio track associated with the video is ignored during the embedding process. [22] These constraints make the model unsuitable for long-form text analysis or applications requiring fine-grained detail from high-resolution imagery or audio-visual content.
Specialized and Third-Party Models (ImageBind)
The Vertex AI Model Garden extends the platform's capabilities by offering access to cutting-edge models from third parties, such as Meta's ImageBind. [24]
ImageBind represents a significant step forward in multimodal understanding, capable of generating joint embeddings across seven distinct modalities: text, image, video, audio, depth, thermal, and inertial measurement units (IMU). Its training methodology allows for "emergent" zero-shot capabilities, meaning it can perform cross-modal retrieval between pairs of modalities it was not explicitly trained on (e.g., audio-to-text search). The availability of such models in the Model Garden provides a pathway for architects to build highly specialized applications that go beyond the capabilities of Google's native multimodalembedding@001 model. [24]
1.3 A Framework for Model Selection and Cost Management
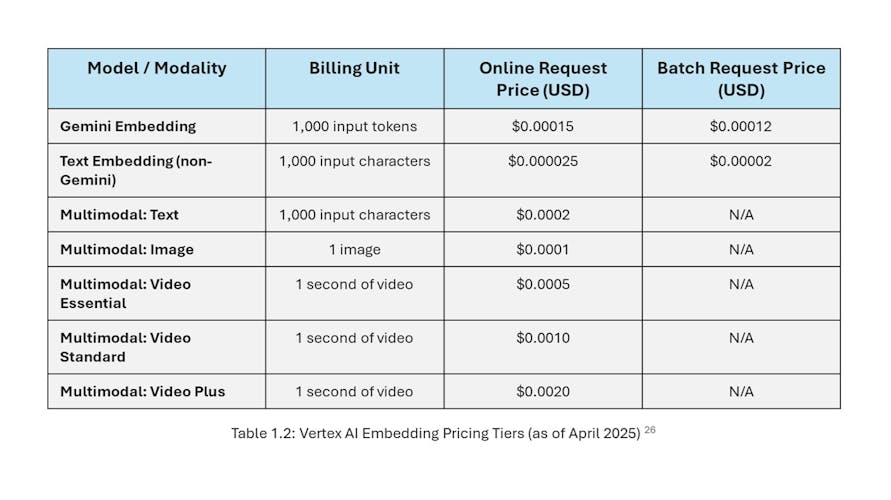
Choosing the right embedding model is a multi-faceted decision that balances performance, cost, and system architecture. The hidden cost of performance is often dimensionality. The highest-performing text model, gemini-embedding-001, achieves its state-of-the-art results in part due to its large 3072-dimensional vectors. [7] An architect's decision to use this model is therefore not a simple change to an API endpoint; it is a fundamental system design choice. The resulting 4x increase in vector size compared to the 768-D vectors of text-embedding-005 has a cascading effect, increasing storage requirements in databases like BigQuery or Cloud Storage, and heightening the computational load on vector search services. This phenomenon, often referred to as the "curse of dimensionality," means that distance calculations in higher-dimensional spaces are more expensive. [25] The outputDimensionality parameter, available for both text and multimodal models, thus becomes a critical tool for managing this trade-off, allowing developers to truncate vectors to a lower dimension to reduce operational costs at the expense of some semantic precision [4]
The pricing structure further complicates this decision. Costs are not uniform across models or data types. Text models are billed differently—Gemini models are billed per 1,000 tokens, and older models are billed per 1,000 characters, with distinct rates for online (low-latency) and batch (high-throughput) requests. Multimodal embeddings introduce further complexity, with separate pricing per image, per 1,000 characters of text, and per second of video. Video pricing is further tiered into "Essential," "Standard," and "Plus" modes based on the density of embeddings generated per minute, a direct function of the interval_sec parameter in the API call. [22] A clear understanding of these pricing models is essential for accurate cost forecasting and for designing cost-effective data processing pipelines.
2. Strategic Application and Known Limitations of Embedding Models
With a clear understanding of the available models, the focus shifts to their strategic application. Effectively leveraging embeddings requires moving beyond simple API calls to implement sophisticated architectural patterns and navigate the practical limitations inherent in the technology. Building an embedding-based application is fundamentally an exercise in MLOps and data engineering. The model is but one component in a larger system that must include robust data preprocessing pipelines, specialized databases for vector storage and retrieval, and careful metadata management.
2.1 Advanced Implementation Patterns for Core Use Cases
Embedding models are the engine for a variety of advanced AI applications. The most prominent patterns include:
- Retrieval-Augmented Generation (RAG): This has become the canonical architecture for grounding Large Language Models (LLMs) in factual, domain-specific, or up-to-date information. [27] The process involves first embedding a corpus of documents (e.g., internal wikis, product manuals, financial reports) and storing these vectors in a specialized vector database, such as Vertex AI Vector Search. [1] When a user submits a query, the application embeds the query text and uses the vector database to retrieve the most semantically similar document chunks. These retrieved chunks are then prepended to the original query and sent as context to an LLM. This allows the LLM to generate an answer based on the provided information, significantly reducing the likelihood of "hallucination" and enabling it to answer questions about data it was not trained on. [27]
- Semantic Search: Unlike traditional keyword-based search, which relies on exact term matching, semantic search uses embeddings to find documents based on their conceptual meaning and intent. [15] A query for "summer vacation outfits" could return documents containing "beachwear," "shorts," and "sandals," even if the original query terms are absent. This is achieved by comparing the vector of the search query with the vectors of all documents in the index and returning those with the highest similarity (i.e., smallest distance in the vector space). [3]
- Classification, Clustering, and Anomaly Detection: Embeddings serve as powerful, high-quality features for a wide range of downstream machine learning tasks.
- Classification: Instead of training a complex model on raw text, one can generate embeddings for a labeled dataset and then train a much simpler and faster classifier (e.g., logistic regression, a small neural network) on these fixed-size vectors. [1]
- Clustering: By applying clustering algorithms (e.g., K-Means) to the embeddings of a large, unlabeled text corpus, one can discover hidden thematic groups or trends within the data. [1]
- Anomaly Detection: This can be framed as a clustering problem where outliers are identified as data points whose embeddings are far from any cluster centroid. This is useful for applications such as fraud detection or content moderation, where anomalous behavior or content requires flagging. [29]
2.2 Optimizing for Intent: A Deep Dive into the task_type Parameter
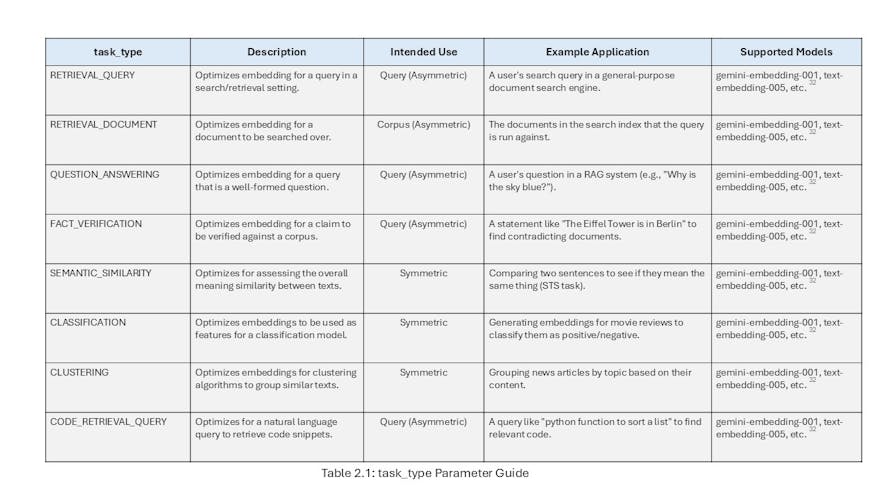
Perhaps one of the most powerful yet subtle features of Vertex AI's newer text embedding models (e.g., gemini-embedding-001, text-embedding-005) is the task_type parameter. [32] This feature represents a paradigm shift from generic embeddings to task-optimized embeddings, providing a form of "soft" fine-tuning at inference time. Traditionally, to optimize embeddings for a specific task, such as question-answering, an engineer would need to undertake the costly and complex process of fine-tuning a dual-encoder model on a large, labeled dataset of question-answer pairs. [29] The task_type parameter democratizes this capability by allowing the developer to signal the intended downstream application to the pre-trained model via the API.4 The model then leverages its extensive training to produce a vector representation optimized for that specific task, dramatically improving performance. [34]
This places a new responsibility on the architect: to correctly identify and apply the appropriate task_type for each piece of text being embedded. These tasks fall into two main categories:
- Asymmetric Use Cases: These involve comparing two pieces of text that have different roles, such as a short query and a long document. For these scenarios, different task_type values must be used for the query and the corpus. For example, in a RAG system, the corpus documents should be embedded with task_type=RETRIEVAL_DOCUMENT, while user questions should be embedded with task_type=QUESTION_ANSWERING. This trains the model to understand the specific relationship between a question and a document that contains its answer, which is distinct from mere topical similarity. [4]
- Symmetric Use Cases: These involve comparing texts of a similar nature, such as when clustering documents or determining the semantic similarity between two sentences. In these cases, the same task_type (e.g., CLUSTERING or SEMANTIC_SIMILARITY) is used for all inputs. [4]
If a specific use case does not clearly map to one of the defined types, the recommended default is RETRIEVAL_QUERY. [32]
2.3 Navigating Practical Limitations and Mitigation Techniques
Despite their power, embedding models have practical limitations that require careful engineering to overcome.
- Input Token Limits and Document Chunking: A universal challenge is the fixed input token limit of all text models (e.g., 2048 tokens for text-embedding-005). [4] For any document that exceeds this limit, a chunking strategy is required. A naive approach of simply splitting the document into non-overlapping chunks and embedding each one is suboptimal. A more significant flaw is averaging the embeddings of these chunks to create a single vector for the entire document. This approach fundamentally misunderstands the nature of embeddings, as it flattens the document's hierarchical structure and averages out distinct topics, resulting in a significant loss of context and a "muddy," less representative final vector. [35] A more robust mitigation strategy is to use overlapping chunks. For example, a long document can be split into 1500-token chunks with a 500-token overlap between consecutive chunks. This ensures that the context from the end of one chunk is present at the beginning of the next, helping the model maintain semantic continuity across the document. [35]
- Context Loss in Asymmetric Tasks: As previously noted, in many retrieval tasks, the query and the desired document are not semantically similar in a direct sense. A question like "What is the capital of France?" is semantically distant from its answer, "Paris." A generic similarity search might fail to make this connection. This is precisely the problem that the asymmetric task_type parameters are designed to solve. By using QUESTION_ANSWERING for the query and RETRIEVAL_DOCUMENT for the corpus, the embedding space is warped to bring questions closer to their corresponding answers, thereby overcoming the context gap. [1]
- Multimodal Limitations: The multimodalembedding@001 model, while versatile, has stringent limitations that must be considered. The 32-token limit for text inputs, restriction to English only, and the complete disregard for audio in video files severely constrain its applicability. [22] Furthermore, like many current-generation multimodal models, it struggles with tasks that require deep cross-modal alignment or complex spatial reasoning (e.g., understanding the relative positions of multiple objects described in a text prompt). [36] For applications requiring more advanced multimodal capabilities, exploring specialized models like
ImageBind from the Model Garden is a necessary step. [24] - The Need for Fine-Tuning: While foundation models provide a powerful baseline, their performance can be significantly enhanced for niche domains through fine-tuning. By training a base model (like text-embedding-005) on a custom, domain-specific dataset (e.g., question-answer pairs from internal financial documents), an organization can create a model that deeply understands its specific vocabulary and semantic relationships. [37] This process, though more involved than using a pre-trained model, is often a crucial step for achieving production-grade accuracy in specialized applications. An added benefit is that the resulting tuned model is a user-owned artifact, insulating it from the potential deprecation of the original publisher model. [14]
3. High-Performance Vector Operations in Python
Once embeddings are generated, the core of many AI applications involves their mathematical manipulation, primarily calculating distances and finding nearest neighbors. Performing these operations efficiently at scale requires a shift from standard Python programming paradigms to optimized, vectorized computation and the use of specialized libraries for Approximate Nearest Neighbor (ANN) search.
3.1 Foundational Vector Mathematics: NumPy vs. SciPy
The bedrock of numerical computation in Python is the NumPy library. It achieves its remarkable performance by delegating array operations to highly optimized, pre-compiled C and Fortran code, bypassing the interpretive overhead of native Python loops. This "vectorization" enables element-wise operations on entire arrays simultaneously, resulting in significant speed improvements, especially for large datasets. [39]
A fundamental operation in vector analysis is calculating the cosine similarity between two vectors. This can be implemented directly with NumPy to build a clear understanding of the underlying mathematics. The formula for cosine similarity between two vectors A and B is:
Sc(A,B)=∥A∥∥B∥A⋅B
This translates directly into NumPy code:
import numpy as np
def cosine_similarity_numpy(vec_a, vec_b):
"""Calculates cosine similarity between two NumPy arrays."""
dot_product = np.dot(vec_a, vec_b)
norm_a = np.linalg.norm(vec_a)
norm_b = np.linalg.norm(vec_b)
# Handle potential division by zero for zero-vectors
if norm_a == 0 or norm_b == 0:
return 0.0
return dot_product / (norm_a * norm_b)
This implementation, using np.dot() for the dot product and np.linalg.norm() for the L2 norm (magnitude), is highly efficient. [40]
For convenience, higher-level libraries provide abstractions for this calculation. Both SciPy and scikit-learn offer functions for this purpose. However, it is critical to note a key difference:
- scipy.spatial.distance.cosine(u, v) calculates the cosine distance, which is defined as 1−similarity. To get the actual similarity score, one must subtract the result from 1. [41]
- sklearn.metrics.pairwise.cosine_similarity(X, Y) directly calculates the cosine similarity and is particularly useful for efficiently computing the similarity matrix between two sets of vectors. [41]
3.2 Distance Metrics in High-Dimensional Space: Cosine Similarity vs. Euclidean Distance
The choice of distance metric is not arbitrary; it has profound implications for the behavior of a search or clustering system.
- Euclidean Distance: This is the familiar straight-line or "as the crow flies" distance between two points in a vector space. It is sensitive to both the direction and the magnitude of the vectors.
- Cosine Similarity: This metric measures the cosine of the angle between two vectors. It is only sensitive to the orientation (direction) of the vectors and is invariant to their magnitude. [42]
For text embeddings, cosine similarity is almost always the preferred metric for measuring similarity. The semantic meaning of a piece of text is encoded in the direction of its embedding vector. Non-semantic factors, such as the length of the document or the frequency of common words, can often influence the magnitude of the vector. Using Euclidean distance would incorrectly penalize two documents that are semantically identical but differ in length. Cosine similarity, by ignoring magnitude, provides a more robust measure of semantic relatedness. [25]
A crucial point of understanding is the relationship between these two metrics when the vectors are normalized (i.e., scaled to have a magnitude or L2 norm of 1). For two normalized vectors u and v, the squared Euclidean distance DE2 is directly related to the cosine similarity Sc:
DE2(u,v)=∥u−v∥2=∥u∥2−2(u⋅v)+∥v∥2=1−2Sc(u,v)+1=2(1−Sc(u,v))
This monotonic relationship means that for normalized vectors, a smaller Euclidean distance corresponds directly to a higher cosine similarity. Consequently, both metrics will produce the exact same ranking of nearest neighbors.42 Even in this case, cosine similarity is often preferred for its computational efficiency (a dot product is faster than a sum of squared differences) and its intuitive, bounded scale of [-1, 1]. [25]
3.3 Scaling Similarity Search with Approximate Nearest Neighbor (ANN) Algorithms
Calculating the exact nearest neighbors for a query vector in a large dataset (a "brute-force" search) requires comparing the query vector to every single other vector in the index. This approach has a computational complexity of O(N⋅d), where N is the number of vectors and d is their dimensionality. For datasets with millions or billions of vectors, this becomes computationally prohibitive and cannot meet the low-latency requirements of real-time applications.
Approximate Nearest Neighbor (ANN) search algorithms solve this problem by trading a small, controllable amount of accuracy for a massive reduction in search time. [27] Instead of guaranteeing the absolute nearest neighbors, they aim to find "good enough" neighbors with very high probability, but in a fraction of the time. This is achieved by pre-processing the data into an intelligent index structure (e.g., using clustering, graph-based methods, or quantization) that allows the search space to be pruned dramatically at query time. [28] This accuracy-for-speed trade-off is the core technology that enables large-scale, low-latency vector search.
3.4 A Comparative Implementation Guide: Faiss vs. ScaNN
The Python ecosystem offers several high-performance open-source libraries for ANN search. Two of the most prominent are Faiss and ScaNN, originating from Meta AI and Google Research, respectively. The choice between them is an architectural decision tied directly to the specific requirements of the application, the embedding model used, and the available hardware.
- Faiss (Facebook AI Similarity Search): Faiss is a mature and highly flexible library written in C++ with complete Python wrappers. [44]
- Strengths: Its primary advantage is its versatility and comprehensive support for GPU acceleration. Faiss offers a vast array of indexing algorithms, from simple baselines like IndexFlatL2 (brute-force) to complex, memory-efficient indexes like IndexIVFPQ (Inverted File with Product Quantization). The ability to offload both index building and search operations to a GPU makes it exceptionally fast for high-throughput scenarios on appropriate hardware. [44]
Implementation Example (IVFPQ Index):
import numpy as np
import faiss
d = 768 # Vector dimensionality
nb = 100000 # Database size
nq = 1000 # Number of queries
# Generate some random data
xb = np.random.random((nb, d)).astype('float32')
xq = np.random.random((nq, d)).astype('float32')
nlist = 100 # Number of clusters (Voronoi cells)
m = 8 # Number of subspaces for Product Quantization
quantizer = faiss.IndexFlatL2(d) # The quantizer for the inverted file
index = faiss.IndexIVFPQ(quantizer, d, nlist, m, 8) # 8 bits per sub-vector
# Train the index on the data
index.train(xb)
# Add vectors to the index
index.add(xb)
# Search the index
k = 10 # We want to find the 10 nearest neighbors
D, I = index.search(xq, k) # D: distances, I: indices
- ScaNN (Scalable Nearest Neighbors): ScaNN is Google's library, optimized for high-performance, in-memory search on CPUs. [18]
- Strengths: ScaNN's key innovation is its use of anisotropic vector quantization, which is particularly effective in minimizing quantization error for inner-product and cosine similarity, resulting in higher accuracy at a given speed compared to other methods. [45] It is designed for maximum speed and efficiency in CPU-based environments but notably lacks GPU support. [45]
Implementation Example:
import numpy as np
import scann
# Generate some random data
dataset = np.random.rand(100000, 128).astype(np.float32)
queries = np.random.rand(1000, 128).astype(np.float32)
# Build the ScaNN searcher
searcher = scann.scann_ops_pybind.builder(dataset, 10, "dot_product").tree(
num_leaves=2000, num_leaves_to_search=100, training_sample_size=250000
).score_ah(2, anisotropic_quantization_threshold=0.2).reorder(100).build()
# Search the index
neighbors, distances = searcher.search_batched(queries)
The selection between these libraries is a critical architectural choice. For a system using a very high-dimensional model like gemini-embedding-001 (3072-D) and facing high query volumes, the computational load of vector comparisons can become a significant bottleneck on CPUs. In such a scenario, Faiss's ability to leverage GPU acceleration may be the only way to meet strict performance SLAs. Conversely, for a system using a lower-dimensional model (e.g., 768-D) deployed on standard CPU-based infrastructure, ScaNN's highly optimized CPU performance may offer the best balance of speed, accuracy, and operational simplicity. The choice of embedding model, ANN library, and deployment hardware is therefore tightly coupled and must be considered holistically.
4. Architecting and Deploying on Google Cloud Run
The final stage of this process involves synthesizing the embedding models and vector math principles into a robust, scalable, and high-performance Python application, deployed on Google Cloud Run. While Cloud Run offers a powerful "serverless" abstraction, achieving optimal performance for demanding ML workloads requires a nuanced understanding of its configuration options and a disciplined approach to containerization.
4.1 Optimizing Cloud Run for CPU-Intensive ML Workloads
For a vector search API, which is both memory-intensive (to hold the index) and CPU-intensive (to perform searches), the default Cloud Run settings are often suboptimal. The "serverless" abstraction is thin; engineers must engage in low-level performance tuning to meet production requirements.
This optimization is a balancing act across three distinct sources of latency: the container cold start, the application cold start, and the per-request processing time.
- Container Cold Start Latency: This is the time it takes for Cloud Run to pull the container image and start the container process. It can be mitigated by creating lean, minimal Docker images and, more definitively, by setting a minimum number of instances (min-instances) to 1 or higher. This keeps a container perpetually "warm" and ready to serve traffic, completely eliminating this latency source at the cost of paying for an instance even when it is idle. [47]
- Application Cold Start Latency: Once the container starts, the Python application must initialize itself. For our vector search service, this is dominated by the time it takes to load the large ANN index file from storage (e.g., GCS) into memory. This latency can be significantly reduced by enabling Startup CPU Boost. This feature, configured via the run.googleapis.com/startup-cpu-boost: 'true' annotation in service.yaml, temporarily allocates more CPU power to the instance during its startup phase, accelerating file I/O and model loading. [47]
- Request Processing Latency: This refers to the time required to process a single API request. It is primarily composed of the network latency of calling the Vertex AI API to embed the query and the CPU time required for the ANN search. This can be optimized by:
- CPU Allocation: For services that require consistent responsiveness, selecting the "CPU always allocated" billing model is often necessary. While more expensive than the default "CPU allocated only during request processing," it ensures that the CPU is immediately available and not throttled down between requests, which is critical for CPU-bound computations. [50]
- Concurrency: Cloud Run can send multiple requests to a single container instance simultaneously. While it might seem intuitive to set concurrency to 1 for a CPU-bound task, this can be inefficient if the application has any I/O-bound components (like the API call to Vertex AI). Using an asynchronous web framework like FastAPI allows the server to handle other requests while waiting for the I/O to complete. Therefore, a concurrency setting slightly greater than 1 (e.g., 2-4) can improve overall throughput. The optimal value must be determined through load testing to find the point of CPU saturation. [47]
4.2 Containerization Best Practices for a FastAPI Application
A well-crafted Dockerfile is the foundation of a secure, efficient, and fast-starting Cloud Run service.
Dockerfile
# ---- Base Stage ----
# Use an official, slim Python base image for a smaller footprint.
FROM python:3.11-slim as base
# Set environment variables to prevent Python from writing.pyc files and to buffer output.
ENV PYTHONDONTWRITEBYTECODE 1
ENV PYTHONUNBUFFERED 1
# ---- Builder Stage ----
# This stage installs dependencies, which are cached if requirements.txt doesn't change.
FROM base as builder
# Set the working directory.
WORKDIR /app
# Install build dependencies.
RUN pip install --upgrade pip
# Copy and install Python dependencies.
# Using --no-cache-dir keeps the image layer smaller.
COPY requirements.txt.
RUN pip wheel --no-cache-dir --wheel-dir /app/wheels -r requirements.txt
# ---- Final Stage ----
# This is the final, lean production image.
FROM base as final
WORKDIR /app
# Copy installed dependencies from the builder stage.
COPY --from=builder /app/wheels /wheels
RUN pip install --no-cache --find-links /wheels /wheels/*
# Create a non-privileged user to run the application.
RUN addgroup --system nonroot && adduser --system --ingroup nonroot nonroot
USER nonroot
# Copy the application code.
COPY./src.
# Expose the port the app runs on.
EXPOSE 8080
# The CMD instruction uses the "exec" form to ensure proper signal handling
# for graceful shutdowns in Cloud Run.
# Use Uvicorn with multiple workers to leverage multiple CPU cores.
# The number of workers should be tuned based on the allocated vCPUs.
# A common starting point is (2 * num_cores) + 1.
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8080", "--workers", "4"]
This Dockerfile incorporates several best practices:
- Multi-stage Builds: A builder stage is used to install dependencies, and only the resulting artifacts are copied to the final stage. This keeps the final image lean and free of unnecessary build tools. [53]
- Dependency Caching: requirements.txt is copied and installed in a separate layer before the application code. This leverages Docker's layer caching, so dependencies are not reinstalled on every code change. [53]
- Non-root User: The application is run as a non-privileged user (non-root), a crucial security best practice. [47]
- Uvicorn with Workers: The CMD instruction starts the application using Uvicorn, a high-performance ASGI server. The --workers flag launches multiple Uvicorn processes, allowing the application to leverage multiple CPU cores available on the Cloud Run instance and achieve true parallelism for CPU-bound tasks, as Python's Global Interpreter Lock (GIL) is per-process.52
- Exec Form CMD: The command is specified in JSON array format (exec form). This ensures that Uvicorn is the main process (PID 1) inside the container and can directly receive termination signals (like SIGTERM) from Cloud Run for a graceful shutdown. [53]
4.3 Infrastructure as Code: A Reference service.yaml
Deploying and configuring a Cloud Run service can be managed declaratively using a service.yaml file. This approach promotes Infrastructure as Code (IaC), ensuring consistent and repeatable deployments.
YAML
# service.yaml
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: vector-search-api
spec:
template:
metadata:
annotations:
# Enable startup CPU boost to accelerate model/index loading.
run.googleapis.com/startup-cpu-boost: 'true'
# Set CPU allocation to always-on for consistent performance.
run.googleapis.com/cpu-allocation: 'always-on'
spec:
# Set a service account with permissions for Vertex AI.
serviceAccountName: [email protected]
containerConcurrency: 4 # Tune based on load testing.
timeoutSeconds: 300 # Set an appropriate timeout for requests.
containers:
- image: gcr.io/your-project-id/vector-search-api:latest
ports:
- containerPort: 8080
resources:
limits:
# Allocate sufficient CPU and memory for the index and search operations.
cpu: "4"
memory: "4Gi"
# Define a startup probe to ensure the service is ready before receiving traffic.
# The probe should check an endpoint that confirms the ANN index is loaded.
startupProbe:
httpGet:
path: "/health/startup"
port: 8080
timeoutSeconds: 240
periodSeconds: 10
failureThreshold: 10
# Configure scaling parameters.
# minScale: 1 # Uncomment to keep one instance warm, eliminating cold starts.
# maxScale: 10
This service.yaml defines a service configured for a high-performance ML workload, specifying CPU allocation, startup boost, concurrency, and resource limits. [49] The startupProbe is particularly important; it tells Cloud Run to wait until the application is fully initialized (i.e., the large ANN index is loaded into memory) before sending it production traffic.
4.4 Reference Implementation: A High-Performance Vector Search API
The following provides the structure and key code components for a FastAPI application that serves as a high-performance vector search API.
Project Structure:
├── Dockerfile
├── requirements.txt
├── service.yaml
└── src/
├── init.py
├── main.py
├── models.py
└── services/
├── init.py
├── embedding_service.py
└── vector_search_service.py
requirements.txt:
fastapi
uvicorn[standard]
pydantic
google-cloud-aiplatform
numpy
faiss-cpu # or faiss-gpu if using a GPU instance
src/models.py (Pydantic Models):
from pydantic import BaseModel, Field
from typing import List
class SearchRequest(BaseModel):
query: str = Field(..., min_length=1, description="The text query to search for.")
top_k: int = Field(5, gt=0, le=100, description="The number of nearest neighbors to return.")
class SearchResult(BaseModel):
id: str
distance: float
class SearchResponse(BaseModel):
results: List
src/services/embedding_service.py:
import vertexai
from vertexai.language_models import TextEmbeddingModel, TextEmbeddingInput
class EmbeddingService:
def init(self, project_id: str, location: str, model_name: str):
vertexai.init(project=project_id, location=location)
self.model = TextEmbeddingModel.from_pretrained(model_name)
def get_embedding(self, text: str, task_type: str) -> list[float]:
"""Generates an embedding for a single text input."""
input_data =
embeddings = self.model.get_embeddings(input_data)
return embeddings.values
# Initialize the service as a singleton
embedding_service = EmbeddingService(
project_id="your-gcp-project-id",
location="us-central1",
model_name="text-embedding-005" # Or gemini-embedding-001
)
src/services/vector_search_service.py:
import faiss
import numpy as np
from typing import List, Tuple
class VectorSearchService:
def init(self):
self.index = None
self.id_map = # Maps index position to original document ID
def load_index(self, index_path: str, id_map_path: str):
"""Loads the Faiss index and ID map from files."""
# In a real application, download these from GCS
print("Loading Faiss index...")
self.index = faiss.read_index(index_path)
print(f"Index loaded with {self.index.ntotal} vectors.")
# Load the ID map (e.g., from a JSON file)
# self.id_map = load_json_file(id_map_path)
def search(self, query_vector: np.ndarray, top_k: int) -> List]:
"""Performs an ANN search on the loaded index."""
if self.index is None:
raise RuntimeError("Index is not loaded.")
# Faiss requires a 2D array for searching
query_vector_2d = np.array([query_vector]).astype('float32')
distances, indices = self.index.search(query_vector_2d, top_k)
results =
for i in range(top_k):
# In a real app, use self.id_map[indices[i]]
doc_id = str(indices[i])
dist = float(distances[i])
results.append((doc_id, dist))
return results
# Initialize the service as a singleton
vector_search_service = VectorSearchService()
src/main.py (FastAPI Application):
from fastapi import FastAPI, HTTPException, Request
from contextlib import asynccontextmanager
import numpy as np
from models import SearchRequest, SearchResponse, SearchResult
from services.embedding_service import embedding_service
from services.vector_search_service import vector_search_service
@asynccontextmanager
async def lifespan(app: FastAPI):
# This code runs on application startup.
# Load the ANN index into memory.
# In a real app, these paths would point to files downloaded from GCS.
vector_search_service.load_index(
index_path="./indexes/my_faiss.index",
id_map_path="./indexes/id_map.json"
)
yield
# This code runs on application shutdown (cleanup).
print("Shutting down...")
app = FastAPI(lifespan=lifespan)
@app.get("/health/startup")
def health_check():
# Startup probe endpoint. Returns 200 OK only if the index is loaded.
if vector_search_service.index is None or vector_search_service.index.ntotal == 0:
raise HTTPException(status_code=503, detail="Service Unavailable: Index not loaded.")
return {"status": "ready"}
@app.post("/search", response_model=SearchResponse)
async def search(request: SearchRequest):
try:
# 1. Embed the user's query using the appropriate task_type.
query_vector = embedding_service.get_embedding(
text=request.query,
task_type="RETRIEVAL_QUERY"
)
# 2. Perform the vector search.
search_results = vector_search_service.search(
query_vector=np.array(query_vector),
top_k=request.top_k
)
# 3. Format the response.
response_results =
return SearchResponse(results=response_results)
except Exception as e:
print(f"An error occurred: {e}")
raise HTTPException(status_code=500, detail="Internal Server Error")
This reference implementation demonstrates key architectural patterns, including the use of FastAPI's lifespan event for one-time initialization of the search index [55], the separation of concerns into distinct services, the utilization of Pydantic for data validation, and the handling of the end-to-end flow from receiving a text query to returning a list of similar document IDs.
5. Conclusion
The landscape of AI application development on Google Cloud is characterized by the rapid evolution of powerful, foundational models, accompanied by a corresponding need for sophisticated architectural patterns to deploy them effectively. The strategic direction of Vertex AI is clear: a consolidation towards highly capable, unified models, such as gemini-embedding-001, which simplify model selection for new projects but necessitate a forward-looking migration strategy for existing systems.
The adoption of these state-of-the-art models introduces a critical architectural trade-off, where superior semantic performance is intrinsically linked to higher vector dimensionality, creating downstream impacts on storage, computational cost, and latency that must be actively managed.
Furthermore, the implementation of features like the task_type parameter marks a significant shift, offering the benefits of task-specific optimization without the prohibitive cost of traditional fine-tuning. This, however, transforms the development process into a data engineering challenge, where the system must be aware of the intent and role of each piece of text, embedding this logic into the data processing pipeline itself.
Finally, deploying these computationally intensive workloads on a serverless platform like Cloud Run requires piercing the abstraction layer. High performance is not an out-of-the-box guarantee but the result of a deliberate and holistic optimization strategy. Architects must balance the three latencies—container, application, and request—by carefully configuring CPU allocation, startup boosts, concurrency, and scaling parameters to optimize performance.
The containerization process itself becomes a critical component of performance, with multi-stage, lean Dockerfiles and parallelized application servers, such as Uvicorn, being prerequisites for success. Ultimately, building a high-performance, vector-based application on Google Cloud is an exercise in integrated system design, where the choice of embedding model, ANN library, application code, and infrastructure configuration is not an independent variable but a set of tightly coupled decisions that collectively determine the system's performance, cost, and scalability.
6. References
- Embeddings | Gemini API | Google AI for Developers, accessed June 29, 2025, https://ai.google.dev/gemini-api/docs/embeddings
- Embeddings APIs overview | Generative AI on Vertex AI - Google Cloud, accessed June 29, 2025, https://cloud.google.com/vertex-ai/generative-ai/docs/embeddings
- Using textembedding-gecko@003 for Vector Embeddings - Google Codelabs, accessed June 29, 2025, https://codelabs.developers.google.com/codelabs/using-textembedding-gecko
- Text embeddings API | Generative AI on Vertex AI - Google Cloud, accessed June 29, 2025, https://cloud.google.com/vertex-ai/generative-ai/docs/model-reference/text-embeddings-api
- State-of-the-art text embedding via the Gemini API - Google Developers Blog, accessed June 29, 2025, https://developers.googleblog.com/en/gemini-embedding-text-model-now-available-gemini-api/
- The State of Embedding Technologies for Large Language Models — Trends, Taxonomies, Benchmarks, and Future Directions. - Medium, accessed June 29, 2025, https://medium.com/@adnanmasood/the-state-of-embedding-technologies-for-large-language-models-trends-taxonomies-benchmarks-and-95e5ec303f67
- Get text embeddings | Generative AI on Vertex AI - Google Cloud, accessed June 29, 2025, https://cloud.google.com/vertex-ai/generative-ai/docs/embeddings/get-text-embeddings
- State-of-the-art text embedding in AlloyDB with the latest Gemini model | by Gleb Otochkin | Google Cloud - Community | May, 2025 | Medium, accessed June 29, 2025, https://medium.com/google-cloud/state-of-the-art-text-embedding-in-alloydb-with-the-latest-gemini-model-ed02f2f564df
- Creating Embeddings for your AI applications with Google Cloud Provider | by muhil varnan, accessed June 29, 2025, https://medium.com/@muhilvarnan.v/creating-embeddings-for-your-ai-applications-with-google-cloud-provider-13e0250c9669
- aimlapi.com, accessed June 29, 2025, https://aimlapi.com/models/text-multilingual-embedding-002-api#:~:text=Language%20Support,it%20suitable%20for%20global%20applications.
- Text-multilingual-embedding-002 - One API 200+ AI Models, accessed June 29, 2025, https://aimlapi.com/models/text-multilingual-embedding-002-api
- How many human languages does text-embedding-ada-002 support? - API, accessed June 29, 2025, https://community.openai.com/t/how-many-human-languages-does-text-embedding-ada-002-support/323175
- Does ada support other languages than English? - API - OpenAI Developer Community, accessed June 29, 2025, https://community.openai.com/t/does-ada-support-other-languages-than-english/185307
- Use embedding models with Vertex AI RAG Engine - Google Cloud, accessed June 29, 2025, https://cloud.google.com/vertex-ai/generative-ai/docs/rag-engine/use-embedding-models
- Embeddings for Text – Vertex AI – Google Cloud console, accessed June 29, 2025, https://console.cloud.google.com/vertex-ai/publishers/google/model-garden/textembedding-gecko
- Vertex AI Embeddings for Text: Grounding LLMs made easy - C2C Global, accessed June 29, 2025, https://www.c2cglobal.com/articles/vertex-ai-embeddings-for-text-grounding-llms-made-easy-5241
- Embeddings for Text – Vertex AI - Google Cloud console, accessed June 29, 2025, https://console.cloud.google.com/vertex-ai/publishers/google/model-garden/textembedding-gecko?hl=zh-cn&invt=Abh9mw&jsmode
- See the Similarity: Personalizing Visual Search with Multimodal Embeddings, accessed June 29, 2025, https://developers.googleblog.com/en/see-the-similarity-personalizing-visual-search-with-multimodal-embeddings/
- Easiest way to AI Search. Multimodal embedding is a technique… | by Uday Chitragar, accessed June 29, 2025, https://medium.com/@uday.chitragar/abc-of-google-multimodal-using-bq-aa78c1ec906d
- Multimodal embeddings API | Generative AI on Vertex AI - Google Cloud, accessed June 29, 2025, https://cloud.google.com/vertex-ai/generative-ai/docs/model-reference/multimodal-embeddings-api
- generative-ai/embeddings/intro_multimodal_embeddings.ipynb at main - GitHub, accessed June 29, 2025, https://github.com/GoogleCloudPlatform/generative-ai/blob/main/embeddings/intro_multimodal_embeddings.ipynb
- Get multimodal embeddings | Generative AI on Vertex AI - Google Cloud, accessed June 29, 2025, https://cloud.google.com/vertex-ai/generative-ai/docs/embeddings/get-multimodal-embeddings
- BigQuery multimodal embeddings and embedding generation | Google Cloud Blog, accessed June 29, 2025, https://cloud.google.com/blog/products/data-analytics/bigquery-multimodal-embeddings-generation
- ImageBind – Vertex AI - Google Cloud Console, accessed June 29, 2025, https://console.cloud.google.com/vertex-ai/publishers/meta/model-garden/imagebind?inv=1&invt=AbiZ0g
- Why Cosine Similarity for Transformer Text Embeddings? : r/learnmachinelearning - Reddit, accessed June 29, 2025, https://www.reddit.com/r/learnmachinelearning/comments/12cp2cg/why_cosine_similarity_for_transformer_text/
- Vertex AI Pricing | Generative AI on Vertex AI | Google Cloud, accessed June 29, 2025, https://cloud.google.com/vertex-ai/generative-ai/pricing
- Top 5 Open Source Vector Databases in 2025 - Zilliz blog, accessed June 29, 2025, https://zilliz.com/blog/top-5-open-source-vector-search-engines
- Using Vertex AI Multimodal Embeddings and Vector Search - GitHub, accessed June 29, 2025, https://github.com/GoogleCloudPlatform/vertex-ai-samples/blob/main/notebooks/official/vector_search/sdk_vector_search_create_multimodal_embeddings.ipynb
- Exploring Embedding Models with Vertex AI - Analytics Vidhya, accessed June 29, 2025, https://www.analyticsvidhya.com/blog/2025/01/embedding-models-with-vertex-ai/
- How Cohere Works with Google's Vertex Machine Engine to Power Embeddings, accessed June 29, 2025, https://cohere.com/blog/vertex-ai
- Understanding and Applying Text Embeddings - DeepLearning.AI, accessed June 29, 2025, https://www.deeplearning.ai/short-courses/google-cloud-vertex-ai/
- Choose an embeddings task type | Generative AI on Vertex AI - Google Cloud, accessed June 29, 2025, https://cloud.google.com/vertex-ai/generative-ai/docs/embeddings/task-types
- Gecko: Versatile Text Embeddings Distilled from Large Language Models - arXiv, accessed June 29, 2025, https://arxiv.org/pdf/2403.20327
- generative-ai/embeddings/task-type-embedding.ipynb at main - GitHub, accessed June 29, 2025, https://github.com/GoogleCloudPlatform/generative-ai/blob/main/embeddings/task-type-embedding.ipynb
- Re: Text embedding on text exceeding limit - is dimension average valid, accessed June 29, 2025, https://www.googlecloudcommunity.com/gc/AI-ML/Text-embedding-on-text-exceeding-limit-is-dimension-average/m-p/881879/highlight/true
- What are the limitations of current multimodal AI models? - Milvus, accessed June 29, 2025, https://milvus.io/ai-quick-reference/what-are-the-limitations-of-current-multimodal-ai-models
- vertex-ai-samples/notebooks/official/generative_ai/tuned_text-embeddings.ipynb at main, accessed June 29, 2025, https://github.com/GoogleCloudPlatform/vertex-ai-samples/blob/main/notebooks/official/generative_ai/tuned_text-embeddings.ipynb
- How to tune embeddings for generative AI on Vertex AI - YouTube, accessed June 29, 2025, https://www.youtube.com/watch?v=o5_t6Ai--ws
- Boosting Python Performance: Exploring the Power of Vectorization vs Loops - Medium, accessed June 29, 2025, https://medium.com/@arthur1cp/boosting-python-performance-exploring-the-power-of-vectorization-vs-loops-de72f3c4a34d
- What is Cosine Similarity and Why Use NumPy? | by whyamit404 - Medium, accessed June 29, 2025, https://medium.com/@whyamit404/what-is-cosine-similarity-and-why-use-numpy-62d409f0661f
- Use sklearn to calculate the cosine similarity matrix among vectors, accessed June 29, 2025, https://danielcaraway.github.io/html/sklearn_cosine_similarity.html
- In practical terms, what differences might you observe in a search system when using cosine similarity instead of Euclidean distance on the same set of normalized embeddings? - Milvus, accessed June 29, 2025, https://milvus.io/ai-quick-reference/in-practical-terms-what-differences-might-you-observe-in-a-search-system-when-using-cosine-similarity-instead-of-euclidean-distance-on-the-same-set-of-normalized-embeddings
- When to use Cosine Similarity over Euclidean Similarity? - GeeksforGeeks, accessed June 29, 2025, https://www.geeksforgeeks.org/when-to-use-cosine-similarity-over-euclidean-similarity/
- facebookresearch/faiss: A library for efficient similarity search and clustering of dense vectors. - GitHub, accessed June 29, 2025, https://github.com/facebookresearch/faiss
- What's the difference between FAISS, Annoy, and ScaNN? - Milvus, accessed June 29, 2025, https://milvus.io/ai-quick-reference/whats-the-difference-between-faiss-annoy-and-scann
- Faiss vs ScaNN on Vector Search - Zilliz blog, accessed June 29, 2025, https://zilliz.com/blog/faiss-vs-scann-choosing-the-right-tool-for-vector-search
- General development tips | Cloud Run Documentation - Google Cloud, accessed June 29, 2025, https://cloud.google.com/run/docs/tips/general
- Cloud Run pricing | Google Cloud, accessed June 29, 2025, https://cloud.google.com/run/pricing
- Configure CPU limits for services | Cloud Run Documentation - Google Cloud, accessed June 29, 2025, https://cloud.google.com/run/docs/configuring/services/cpu
- Re: Cloud Run container stops processing when running parallel Fastapi background tasks, accessed June 29, 2025, https://www.googlecloudcommunity.com/gc/Serverless/Cloud-Run-container-stops-processing-when-running-parallel/m-p/865246
- Key metrics for monitoring Google Cloud Run - Datadog, accessed June 29, 2025, https://www.datadoghq.com/blog/key-metrics-for-cloud-run-monitoring/
- Handling Concurrency in Google Cloud Run with Python | by Akshat Upadhyay - Medium, accessed June 29, 2025, https://medium.com/eatclub-tech/handing-concurrency-in-google-cloud-run-with-python-abe481852041
- FastAPI in Containers - Docker, accessed June 29, 2025, https://fastapi.tiangolo.com/deployment/docker/
- Cloud Run YAML Reference | Cloud Run Documentation - Google Cloud, accessed June 29, 2025, https://cloud.google.com/run/docs/reference/yaml/v1
- Deployments Concepts - FastAPI, accessed June 29, 2025, https://fastapi.tiangolo.com/deployment/concepts/



