


July 18 • 46 min read
Congratulations, Your Resume is Now a List of Floating-Point Numbers!
Is your recruiting software silently rejecting top talent? If it still can’t grasp that a ‘developer’ might call themselves a ‘programmer,’ you’re missing out on hidden talent pools. This article reveals how AI is transforming resumes into ‘embedding vectors’—floating-point numbers that capture meaning, not just keywords—unlocking a semantic moat competitors can’t cross. But beware: this isn’t magic.
In today's competitive hiring market, top candidates are often overlooked by traditional recruiting tools. Outdated systems relying on exact keyword matching frequently overlook top-tier talent simply because they use different job titles or phrasing on their resumes. While your competitors remain stuck in this keyword trap, modern AI offers a decisive advantage.
By leveraging semantic search, which understands the meaning and context of skills and experience, companies can now tap into a "hidden talent pool." This technology identifies qualified professionals with transferable skills or non-standard backgrounds who are often overlooked by competitors relying on lexical search. This creates a powerful information advantage, enabling talent search professionals and hiring managers to discover talent that others may overlook and establish a more strategic, data-driven edge in the war for talent.
For any leader aiming to gain a competitive edge, this article is essential reading. It moves beyond the hype to provide a clear, strategic framework for understanding, implementing, and capitalizing on the AI revolution in recruitment. It details not only the immense opportunities for discovering untapped talent but also the critical challenges, such as cost and algorithmic bias, providing a comprehensive roadmap for navigating the future of hiring.
1. The Semantic Revolution in Recruitment
The talent acquisition industry is undergoing a profound technological transformation, shifting away from the outdated and often ineffective methods of the past toward a more intelligent, context-aware approach. This evolution is driven by advancements in artificial intelligence (AI), specifically in the field of Natural Language Processing (NLP). The core of this shift is the transition from lexical search, which relies on exact keyword matching, to semantic search, which seeks to understand the underlying meaning of language. In this section, we deconstruct the fundamental technological principles driving this revolution, establishing the inadequacy of traditional methods and detailing the core components—embedding vectors and the vector search stack—that enable a more nuanced and powerful approach to connecting talent with opportunity.
1.1. From keywords to context: the inadequacy of lexical search
For decades, lexical search has been the dominant technology in digital recruitment, particularly within Applicant Tracking Systems (ATS).[1] This method functions by matching the exact keywords or phrases present in a recruiter's query to the text within a candidate's resume. While simple Boolean logic (AND, OR, NOT) can refine these searches, the approach is fundamentally limited by its inability to comprehend context, synonyms, or related concepts.[2]
The consequences of this limitation are severe and twofold. First, it generates a high rate of "false negatives," where highly qualified candidates are systematically overlooked because their resumes do not contain the precise terminology used in the job description. For instance, a system searching for a "Sales Representative" might entirely miss candidates who describe themselves as a "Sales Agent" or a "Sales and Service Associate."[1] Similarly, a search for a "developer" could fail to identify an equally qualified "programmer," and a role for a "software architect" might not yield a candidate with identical responsibilities listed under the title "senior software engineer." [3] This vocabulary mismatch forces recruiters to either become experts in Boolean logic to construct exhaustive search strings or risk missing a significant portion of the relevant talent pool.
Second, lexical search can produce "false positives," where keywords match but the context is entirely wrong. The system cannot discern the meaning behind the words, leading to irrelevant results that waste recruiters' time.
The paradigm shift toward semantic search directly addresses these flaws. Powered by AI and NLP, semantic search is engineered not only to match words but also to understand the intent and meaning of the language used in both the job description and the candidate's profile.[2] This technology recognizes that "business intelligence" and "data visualization" are highly relevant skills for a "data analyst" role, even if the candidate never uses the exact title. [6] By mapping the complex relationships between different skills, job titles, and experiences, semantic systems can uncover "hidden talent pools"—candidates who are contextually and competently a perfect fit but remain invisible to legacy keyword-based systems.[7] This capability to expand the viable talent pool while increasing relevance represents a fundamental redefinition of how talent sourcing is performed.[2]
1.2. The Core Technology: An Introduction to Embedding Vectors
The engine that powers semantic search is the embedding vector. An embedding is a dense, high-dimensional numerical representation—a list of floating-point numbers—that captures the semantic essence of a piece of data, such as a word, sentence, or entire document.[4] This process transforms unstructured, human-readable text into a structured, mathematical format that machines can quantitatively compare and analyze.[11] The number of dimensions in a vector, which can range from a few hundred to several thousand, correlates directly with the level of detail and nuance it can represent; higher dimensionality allows for more granular and accurate semantic capture.10
The evolution of embedding models has been central to the increasing sophistication of semantic search:
- Early Models (Word2Vec, GloVe): These foundational models, introduced around 2013, generate static, non-contextual word embeddings.[4] They learn a word's meaning based on its co-occurrence with other words in a massive text corpus (e.g., a dataset of over 1 billion words). For example, the vector for "king" would be mathematically similar to the vector for "queen." While revolutionary at the time, their primary limitation is their inability to differentiate a word's meaning in different contexts. The word "bank" would have the same vector whether it refers to a financial institution or a riverbank.[11]
- Transformer-Based Models (BERT, SBERT, RoBERTa): The development of transformer-based architectures, most notably Google's BERT (Bidirectional Encoder Representations from Transformers), marked a watershed moment for NLP.[4] Unlike its predecessors, BERT generates
contextual embeddings. The vector representation for a word is dynamically created based on the surrounding words in the sentence. This is critically important in the recruitment domain, where a term like "developer" can signify vastly different roles and skill sets depending on the context (e.g., "front-end web developer" vs. "embedded systems developer").[4] Subsequent models, such as SBERT (Sentence-BERT), were specifically fine-tuned to produce semantically meaningful embeddings for entire sentences or paragraphs, making them highly efficient for comparing the similarity between documents, like resumes and job descriptions.[13] Modern frameworks, such as the proposed Resume2Vec, explicitly leverage a suite of these powerful transformer models—including encoders like BERT and RoBERTa and decoders like GPT—to create intelligent, context-rich embeddings from talent data.[14]
The process of generating these embeddings follows a standardized pipeline. First, the raw text data from resumes and job descriptions is prepared through cleaning (removing irrelevant characters) and tokenization (breaking text into words or sub-words). Next, an appropriate embedding model is chosen, which can be a general-purpose pre-trained model, such as one from OpenAI, Google Gemini, or a model fine-tuned for a specific domain. Finally, the prepared data is fed into this model, which outputs the high-dimensional vector embeddings that form the basis for all subsequent semantic operations.[15]
1.3. The Mechanics of Semantic Comparison: The Vector Search Stack
A successful transition to semantic search is not merely the adoption of a single piece of software but the implementation of an entire, interdependent data pipeline. The choice of embedding model, for instance, directly influences the storage requirements and computational load on the database. In contrast, the model itself often dictates the selection of a suitable similarity metric. This holistic architecture, commonly referred to as the vector search stack, comprises several critical components.
- Vector Databases: Once generated, the millions or even billions of high-dimensional vectors representing a talent pool must be stored in a way that allows for rapid retrieval. Standard relational databases are ill-suited for this task. This has given rise to specialized vector databases, such as Pinecone, Weaviate, and Milvus, which are purpose-built to store, index, and query vast collections of high-dimensional data with high speed and efficiency.[4]
- Indexing for Speed: Approximate Nearest Neighbor (ANN) Algorithms: Performing a "brute-force" search—comparing a query vector against every single vector in a massive database—is computationally intractable and would result in unacceptably slow response times.[11] To solve this, vector databases employ Approximate Nearest Neighbor (ANN) search algorithms. The most prominent and widely adopted ANN algorithm is HNSW (Hierarchical Navigable Small World).[16] HNSW builds a sophisticated, multi-layered graph structure during the indexing process. This graph creates "shortcuts" through the data, allowing the search algorithm to navigate the vector space and find the closest matches to a query vector with extraordinary speed, without needing to check every single point. This approach trades a minuscule amount of recall accuracy for a massive gain in performance. The behavior of the HNSW index can be tuned using parameters that allow engineers to balance index build time, query latency, and search accuracy to meet specific application requirements.[11]
- Measuring "Closeness": Similarity Metrics: At the heart of the matching process is the mathematical quantification of the relationship between vectors. The system uses a similarity metric to calculate the "distance" or "closeness" between the query vector (derived from the job description) and the candidate vectors in the database. The most common metrics include:
➤ Cosine Similarity: This is the most widely used metric in semantic search. It measures the cosine of the angle between two vectors. A result of 1 indicates the vectors point in the exact same direction (perfect similarity), 0 indicates they are orthogonal (no similarity), and -1 indicates they point in opposite directions. Its key advantage is that it judges similarity based on the orientation of the vectors, not their magnitude, making it robust to differences in document length.[4]
➤ Euclidean Distance (L2 Norm): This metric calculates the simple, straight-line distance between the endpoints of two vectors in the multi-dimensional space. A smaller distance implies greater similarity.[4]
➤ Dot Product: This metric considers both the angle and the magnitude of the vectors. For vectors that have been normalized (scaled to a length of 1), the dot product is mathematically equivalent to cosine similarity. Still, it can be computationally faster to calculate, offering a performance advantage in large-scale systems.16 The choice of metric is often tied to the embedding model used; for example, Azure OpenAI embedding models are designed to be used with cosine similarity.[16]
By implementing this complete stack, organizations can move beyond the limitations of lexical search. This technological advantage creates a "semantic moat." Companies leveraging this stack are not just finding candidates more efficiently; they are fundamentally accessing a different and larger talent pool. They can identify individuals with transferable skills from adjacent industries or those who describe their qualifications in non-standard ways—talent that is entirely invisible to competitors still relying on keyword matching.[7] This information asymmetry provides a durable competitive edge in the war for talent.
2. The Primary Application: AI-Powered Candidate Scoring and Ranking

The most direct and impactful application of vector embeddings in recruitment is the automated scoring and ranking of candidates against an ideal role profile. This process transforms the subjective and time-consuming task of manual resume review into a data-driven, scalable workflow. In this section, we provide a granular, step-by-step deconstruction of the core application, moving from the high-level workflow to the technical nuances of how a "match score" is engineered and how recruiters can effectively guide the AI system in creating a robust Ideal Candidate Profile (ICP).
2.1. The End-to-End Matching Workflow
The journey from a job opening to a ranked list of qualified candidates follows a systematic, multi-step process powered by the vector search stack.
- Step 1: Defining the Target Profile (The Query): The entire process is initiated by the recruiter defining what they are looking for. This can be a formal Ideal Candidate Profile (ICP) or, more commonly, a detailed job description (JD). This source text serves as the input for the query vector. Modern platforms are designed for ease of use; for instance, Talentprise provides a single input box where a recruiter can type a descriptive paragraph or simply paste the entire job description, which the AI then parses to understand the core requirements.[19] The quality and detail of this initial input are paramount, as it directly dictates the relevance of the search results.
- Step 2: Vectorization of Candidate and Job Data: The system ingests unstructured data from two sources: the target JD and the vast pool of candidate resumes or profiles stored in the ATS. Using a transformer-based embedding model like BERT, it converts the textual content of each document into a high-dimensional vector.[4] A naive implementation might create a single embedding for an entire resume, but this is a blunt instrument. A more sophisticated and necessary approach is to use a multi-embedding strategy. This involves parsing the resume into logical sections—such as work experience, skills, education, and languages—and generating a separate embedding for each. This granularity is crucial because it enables the system to assign different weights to various aspects of a candidate's profile during the scoring phase, reflecting real-world hiring priorities (e.g., giving more importance to experience than to education). [18] Early systems that used a single embedding were found to produce misleading results, for example, by overemphasizing years of tenure rather than the relevance of the experience itself.[18]
- Step 3: Similarity Search and Retrieval: The vector generated from the job description becomes the query. This query vector is then used to search the indexed collection of candidate vectors stored in the vector database. To perform this search efficiently across potentially millions of candidates, the system utilizes an ANN algorithm, such as HNSW. The algorithm rapidly traverses the pre-built graph of candidate vectors to find the 'k' nearest neighbors—the candidates whose profile vectors are mathematically most similar to the job vector.[16]
- Step 4: Scoring and Ranking: Each of the 'k' candidates retrieved from the search is assigned a similarity score based on the chosen distance metric (e.g., cosine similarity). The system then presents the results to the recruiter as a ranked list, with the highest-scoring candidates (those most semantically similar) positioned at the top.8 Platforms like Manatal and Recruiterflow often visualize this score as an intuitive percentage or a color-coded indicator (e.g., green for a strong match) to help recruiters quickly identify the most promising talent.[20]
2.2. Deconstructing the "Match Score"
The "match score" presented to a recruiter is not a raw mathematical output, but a carefully engineered metric designed specifically for ranking. Understanding its composition is crucial for interpreting results and fine-tuning the system effectively.
- From Similarity to Score: Raw similarity metrics can be counterintuitive for ranking. For example, with cosine similarity, a higher value (closer to 1) is better. However, with Euclidean distance or cosine distance (defined as 1−cosine_similarity), a lower value is better. To provide a consistent user experience where a higher score is always better, platforms apply mathematical transformations. Azure AI Search, for instance, converts cosine distance into a monotonically decreasing score using the formula score=1/(1+cosine_distance). This ensures that as similarity worsens (distance increases), the score value reliably decreases. The platform also provides a reverse formula for developers who need to retrieve the original cosine similarity value from the score.16 This engineered nature of the score means that a "95% match" is not an absolute measure but a relative ranking value produced by a proprietary algorithm.
- Advanced Scoring with BERTScore: For applications that require comparing generated text against a reference (a task analogous to comparing a candidate's self-summary to a job's core responsibilities), a more sophisticated metric called BERTScore can be used. Instead of a single similarity value, BERTScore calculates precision, recall, and F1 scores. It does this by aligning each token (word) in the candidate text with the most semantically similar token in the reference text, based on their contextual BERT embeddings. This alignment can be optionally weighted by Inverse Document Frequency (IDF), which gives more importance to rare and specific terms (e.g., a specific technology name) than to common ones (e.g., "managed"). While more computationally intensive, BERTScore provides a much deeper and more explainable measure of semantic equivalence than a simple vector distance.[17]
- Hybrid Search and Reciprocal Rank Fusion (RRF): The most robust recruitment search systems often do not rely on vector search alone. They employ a "hybrid" approach that combines the semantic understanding of vector search with the precision of traditional keyword search. This is useful for queries that contain specific, must-have terms (like a non-negotiable certification, e.g., "PMP-certified"). When a hybrid query is executed, the system gets two separate ranked lists of results—one from the vector search and one from the keyword search. To merge these into a single, coherent final list, a technique called Reciprocal Rank Fusion (RRF) is applied. RRF re-ranks the combined results by giving a score to each document based on the inverse of its rank in each list. This method is more effective and robust than simply normalizing and summing the different scores, consistently producing more relevant results in benchmark tests.[16]

2.3. Crafting the Ideal Candidate Profile (ICP) for AI
The entire sophisticated, multi-million-dollar AI stack is functionally blind without a high-quality, nuanced query to guide it. The creation of the Ideal Candidate Profile (ICP) is therefore the most critical human-in-the-loop task in the entire workflow. A vague query will yield vague results; a precise and detailed query is the recruiter's primary lever for controlling the AI and achieving relevant outcomes.[22]
- Key Components of an Effective ICP: An ICP designed to guide a semantic search engine must go beyond a simple list of keywords. It should be a rich, descriptive document that captures the essence of the role.
🢣 Essential Skills and Experience: This includes a prioritized list of hard skills (e.g., Python, AWS), technical skills, and, crucially, soft skills. Instead of just listing "leadership," the ICP should describe the required competency: "experience leading a remote team of developers on a fast-paced project".[22]
🢣 Job Duties and Responsibilities: A clear, detailed outline of the day-to-day tasks and overarching responsibilities of the role.[22]
🢣 Work Style and Personality Traits: Descriptors that speak to cultural fit are vital. Is the ideal candidate highly independent or deeply collaborative? Adaptable and innovative, or detail-oriented and process-driven?[22]
🢣 Data from Top Performers: One of the most powerful techniques for building an effective ICP is to analyze the profiles of the company's existing top performers in similar roles. By identifying the common skills, experiences, and traits that lead to success, recruiters can reverse-engineer a profile of what "good" looks like and feed those attributes into the ICP. This data-driven approach grounds the search in proven success factors.[22]
- The role of AI in creating the ICP: AI can be a powerful assistant in this process itself. Tools like Carv can ingest the raw input from a hiring manager intake call or an existing job description and automatically generate a structured, comprehensive draft of the ICP. The recruiter can then review, refine, and enrich this draft with their own expertise and insights from top performer analysis. This AI-assisted workflow ensures that the final ICP is not only detailed but also accurately reflects the hiring manager's true vision for the role, bridging a common communication gap in the recruitment process.[22] The implication is clear: the most valuable skill for a recruiter in an AI-powered ecosystem is not manual sourcing, but the strategic ability to analyze a role's requirements and translate them into a comprehensive profile that can effectively steer the AI. Training teams on how to create these high-fidelity ICPs is a critical factor for success.[6]

3. Market Landscape and Ecosystem
The adoption of vector embedding technology has catalyzed the growth of a diverse and dynamic market for AI-powered recruitment tools. The landscape is composed of established ATS providers integrating AI capabilities, specialized startups built from the ground up on semantic search principles, and a range of point solutions targeting specific stages of the hiring funnel. In this section, we provide a high-level overview of some key players (although not exhaustive) and analyze how the technology is packaged and sold, as well as explore the expanding use cases that demonstrate the technology's strategic value beyond simple candidate matching.
3.1. Innovators and Platforms: Who is Using These Models?
The market can be broadly segmented into two categories: large, end-to-end platforms that are embedding AI into their existing suites, and more focused, AI-native tools that specialize in sourcing, screening, or assessment.
- End-to-End ATS with AI: Major players in the HR technology space are actively acquiring or developing AI capabilities to enhance their core Applicant Tracking Systems.
🢣 Workday: A prominent example is Workday, which acquired HiredScore to integrate sophisticated AI features. HiredScore provides unbiased, AI-driven candidate grading and prioritization, helping recruiters surface the best-fit talent from their existing candidate pools. It also offers real-time diversity insights directly within the recruiter's workflow, moving beyond retrospective metrics.[26]
🢣 iCIMS: This platform provides AI-powered candidate ranking and matching capabilities, claiming that its technology enables clients to fill jobs 22% faster and achieve a 282% return on investment.[27]
🢣 Other ATS Platforms: Legacy and modern ATSs, such as Greenhouse, Lever, and Ashby, are also incorporating AI, although the sophistication varies.[21] The most advanced systems are moving beyond simple keyword parsing to integrate true NLP and semantic understanding, often by leveraging technologies from partners like Daxtra or Burning Glass, or by building their capabilities with accessible tools like ChatGPT's API.[29] However, a degree of skepticism is warranted, as some platforms may market simple rule-based logic as "AI".[21] Thorough technical due diligence is necessary to distinguish true semantic systems from those with a marketing veneer.
- Specialized AI Sourcing & Screening Tools: A vibrant ecosystem of specialized vendors has emerged, often with a stronger "AI-native" foundation built around vector search.
🢣 Findem: This talent data platform uses what it calls "3D data"—connecting person and company data over time—to create rich, comprehensive candidate profiles. It focuses on automating top-of-funnel activities to reduce the complexity of the talent tech stack.[30]
🢣 Eightfold AI: A talent intelligence platform that leverages "explainable AI" to not only match candidates to roles but also provide context as to why they are a good fit. It has demonstrated significant ROI in case studies, including a 40% reduction in time-to-hire and a 20% increase in diversity representation for a multinational client.[30]
🢣 hireEZ (formerly Hiretual): A powerful sourcing tool that uses AI-powered filters to search for candidates across more than 45 platforms, including LinkedIn and GitHub. It excels at building highly targeted searches to identify candidates with niche or hard-to-find skill sets.[30]
🢣 RChilli: Provides a dedicated Search & Match Engine that uses NLP and deep learning to pinpoint relevant candidates, including "hidden talent" that might be missed by other systems. It also features intelligent recommendation capabilities, suggesting relevant jobs to candidates and similar candidates to recruiters.[8]
🢣 Talentprise: This platform is built entirely around an AI semantic search engine. Its core feature is a single, descriptive query box that allows recruiters to input natural language, which the AI then uses to find and rank the best-matching candidates from its registered user base.[19]
🢣 Phenom: Offers a comprehensive suite of AI tools, including a "Talent Companion" chatbot for candidate engagement, intelligent semantic search, and Generative AI for creating personalized job descriptions and outreach campaigns.[33]
🢣 Vervoe: An AI-driven skills assessment platform. It analyzes a job description to automatically generate role-specific assessments (e.g., coding challenges, portfolio reviews). Then it uses a 0-10 scoring system, graded by AI, to evaluate and rank candidates based on their performance.[34]
🢣 eBoss: An ATS that heavily promotes its semantic search engine, which it claims can reduce talent sourcing time by 80% through its contextual understanding of recruiter queries.[35]
3.2. Beyond Candidate Matching: Expanded Use Cases
The strategic value of vector embedding technology extends far beyond simply finding and ranking external candidates. The ability to semantically understand and query talent data unlocks a range of applications that can transform an organization's entire talent management lifecycle. The most profound impact of this technology may not be in finding new candidates, but in activating and understanding the value of an organization's existing data, both in its applicant pool and its current workforce.
- Talent Rediscovery: One of the most valuable applications is the ability to mine an organization's existing ATS database. Companies often sit on a goldmine of data from every candidate who has ever applied. With lexical search, this data is essentially inert and difficult to search effectively. Semantic search, however, enables the dynamic rediscovery of talent. As new roles open up or business needs evolve, the system can re-query the entire history of applicants to find individuals who are now a perfect fit for a position for which they were previously unqualified. A candidate who applied for a junior role two years ago may now have the requisite experience for a senior position. This capability dramatically shortens the time-to-hire and slashes recruitment costs by tapping into a warm pool of candidates already familiar with the company.[7]
- Internal Mobility: The same semantic matching technology can be turned inward to foster internal mobility and employee retention. By mapping the skills and experiences of current employees, the system can identify internal candidates with transferable skills who are a strong match for open positions within the company. This helps employees discover new growth opportunities and enables the organization to retain top talent. Semantic search is particularly effective in this context, as it can identify latent potential and adjacent skills in employees that managers or traditional keyword-based internal job boards may overlook.2 Platforms like Fuel50 are specifically designed for this purpose, using AI to match employees to internal roles, projects, and mentorship opportunities.[30]
- Predictive Analytics for Hiring Success: By analyzing the historical data of successful (and unsuccessful) hires, AI models can identify the patterns and attributes that correlate with high performance, long tenure, and strong cultural fit. These predictive insights can then be applied to the current candidate pool, enabling recruiters to prioritize individuals who not only possess the right skills for the job today but also have a higher statistical likelihood of thriving in the organization long-term. This shifts the focus from reactive recruiting to proactive, data-informed talent strategy.[33]
- Automated and Personalized Outreach: Generative AI, powered by the same underlying transformer models, can be utilized to craft highly personalized outreach messages. By analyzing a candidate's profile, the AI can craft an email or InMail that references their specific projects, skills, and interests, leading to significantly higher engagement and response rates compared to generic, templated messages.[33]
- Talent Market Mapping: AI tools can aggregate and analyze data from across the web to provide a strategic, "bird's-eye view" of the talent landscape. These tools can create visualizations showing the geographical distribution of specific skill sets, identify which competitor companies have the highest concentration of target talent, and track skill trends over time. This market intelligence allows recruitment teams to focus their sourcing efforts more strategically.[23]
This expansion of use cases demonstrates a critical shift in the value proposition of recruitment technology. The focus moves from a transactional "fill this requisition" model to a holistic "manage our talent ecosystem" model, where data is a dynamic, perpetually valuable asset for both acquiring and developing talent.
4. Critical Challenges and Inherent Limitations
While the promise of AI-driven recruitment is substantial, its implementation is fraught with significant challenges that require careful consideration. The technology is not a panacea; it introduces new complexities, operational hurdles, and profound ethical dilemmas. Let's delve into a critical analysis of these limitations, focusing on the technical difficulties of implementation, the pervasive and concerning issue of algorithmic bias, and the "black box" problem that necessitates a shift toward more transparent and explainable systems.

4.1. Technical and Operational Hurdles
Deploying and maintaining a high-performance vector search system for recruitment is a complex engineering endeavor that involves striking a balance among cost, speed, and accuracy.
- Scalability and Performance: As a talent database grows to include millions of candidate profiles, maintaining low-latency query performance becomes a primary challenge. High-dimensional embeddings are computationally expensive to search. This requires not only the use of ANN algorithms, such as HNSW, but also their careful tuning. Furthermore, the infrastructure required to store and process these large vector indexes can be substantial, demanding significant memory and computational resources to handle real-time query loads without degradation.[18]
- Cost: The financial investment can be considerable. Using state-of-the-art pre-trained embedding models from providers like OpenAI involves paying for API calls, which can become expensive at high volume. Alternatively, training or fine-tuning custom models requires investment in specialized ML engineering talent and the powerful GPU infrastructure needed for the task. The ongoing costs of cloud storage for vector databases and compute resources for querying also contribute to the total cost of ownership.[40]
- Embedding Quality and Consistency: The system's effectiveness is fundamentally dependent on the quality of the embeddings, which is a direct reflection of the quality of the input data. The "garbage in, garbage out" principle is paramount. Resumes with vague or non-descriptive entries, such as a job title of "Outsourcer specialist" with no further detail, will produce noisy, misleading embeddings that pollute search results and reduce matching quality.[18] An additional complication is model versioning. When an embedding model is updated or replaced, the new vectors it produces may not be semantically compatible with the old vectors already in the database. This can break search and clustering functionalities, requiring a complete and costly re-embedding of the entire database or the implementation of complex versioning strategies.[39]
- Domain-Specific Language (Jargon): Most general-purpose embedding models are trained on massive, diverse datasets from the public web. While this provides them with a broad understanding of language, they often struggle with the particular and nuanced jargon of specialized industries, such as finance, law, or medicine. A general model may not capture the subtle yet critical differences between financial instruments or legal precedents, resulting in underperformance and irrelevant matches in these domains.[40]
- Handling Multilingual Data: For global organizations, supporting a talent pool with resumes in multiple languages presents a significant challenge. One approach is to use a single, large multilingual embedding model. However, these models often exhibit lower performance on any single language compared to a model trained specifically on that language. The alternative is to implement a pipeline that first translates all non-English content into English and then uses a high-performance English-only embedding model. While this approach can yield better results, it introduces the complexity and potential for error associated with a machine translation step.[18]
- Capturing Nuance (Soft Skills): This remains one of the most significant unsolved problems. Vector embeddings excel at matching explicit, quantifiable hard skills and experiences. They struggle, however, to interpret the qualitative nuance of soft skills. A model can easily match the keyword "React," but it has difficulty distinguishing between a candidate who merely "used React" on a small project and one who "architected and maintained large-scale, production-level React applications".[18] Recruiters understand that soft skills are best demonstrated by showing, not telling—utilizing quantified achievements and structured narratives, such as the STAR method (Situation, Task, Action, Result), to provide concrete evidence of competencies like leadership or problem-solving.[44] An embedding model cannot inherently understand such a narrative structure without being specifically prompted or fine-tuned to recognize these patterns. This technological gap means that AI is a powerful tool for initial screening based on hard skills, but assessing deep expertise and crucial soft skills remains a task that requires human judgment.
4.2. The Pervasive Issue of Algorithmic Bias
Perhaps the most critical challenge in AI recruitment is algorithmic bias. The industry narrative often presents AI as a tool to reduce human bias.[2] While these systems can mitigate certain types of bias, such as a recruiter's personal affinity or the bias of keyword exclusion, they simultaneously introduce a more insidious and systemic form of bias that is learned from historical data. This does not eliminate bias; it merely changes its form from an explicit, observable prejudice to a hidden, mathematically justified one, operating under the guise of objectivity.

- The Core Problem: AI models are not objective. They are pattern-recognition machines. When trained on historical hiring data, they learn the patterns within that data, including the societal and organizational biases that influenced past decisions. The model will learn to replicate and, in many cases, amplify these biases at scale.[46]
- The Amazon Case Study: The most famous cautionary tale is Amazon's experimental AI recruiting tool. The model was trained on a decade of the company's hiring data, which was predominantly from male candidates. As a result, the AI learned that male profiles were preferable and began to systematically penalize resumes that contained the word "women's" (e.g., "women's chess club captain") and downgrade graduates of all-women's colleges. Upon discovering this discriminatory behavior, Amazon commendably scrapped the project before it was ever used for actual hiring decisions.[46]
- Sources of Bias:
🢣 Data Bias: This is the most common source of bias. The training data may contain a skewed sample, where one demographic is disproportionately represented in successful outcomes (e.g., historical data shows more male engineers being hired). It can also contain tainted labels, where the outcome being predicted (e.g., a "good hire" label) was assigned by a human recruiter whose own unconscious biases influenced the decision.[46]
🢣 Feature and Proxy Bias: Even if protected attributes, such as race and gender, are explicitly removed from the data, AI models are adept at identifying proxies for them. Attributes like the college a person attended, the zip code they live in, or even the specific phrasing they use can be statistically correlated with protected characteristics. The model can learn these correlations and use them to make discriminatory decisions. A 2024 study from the University of Washington demonstrated this starkly: when given identical resumes where only the name was changed, leading AI models favored white-associated names 85% of the time and preferred other candidates over Black men nearly 100% of the time.[46]
🢣 Intersectional Bias: Bias can be compounded for individuals who belong to multiple marginalized groups. The effects of gender bias and racial bias can intersect, creating a unique and more severe disadvantage for groups like Black women, which a simple analysis of each bias in isolation would miss.[49]
4.3. The "Black Box" Problem and the Rise of Explainable AI (XAI)
Compounding the issue of bias is the inherent opacity of many advanced AI models. Deep neural networks, in particular, often function as "black boxes," making it exceedingly difficult for humans to understand why a specific decision or prediction was made.[54] In a high-stakes, highly regulated domain such as hiring, this lack of transparency poses a significant legal, ethical, and reputational risk. If a candidate is rejected, the organization may be unable to provide a coherent reason, which could expose it to litigation.[56]
Explainable AI (XAI) has emerged as a critical field of research and development to address this challenge. XAI refers to a set of methods and systems designed to make the decision-making process of an AI model understandable to humans.[54]
In the context of recruitment, an XAI-enabled system would not simply provide a ranked list of candidates; instead, it would offer a more nuanced understanding of the candidate's suitability. Instead, for each recommended candidate, it would explain its reasoning. For example, it might highlight the specific skills, experiences, or quantified achievements from the resume that contributed most to their high match score. This transparency allows recruiters to:
- Audit the AI's Logic: Verify that the model is making decisions based on relevant, job-related criteria.
- Build Trust: Gain confidence in the system's recommendations by understanding their basis.
- Detect and Mitigate Bias: Spot patterns where the AI may be relying on inappropriate proxies or exhibiting biased behavior, and then take corrective action.[57]
Recognizing the importance of transparency, several vendors, including Eightfold AI and TalentRx™, are now explicitly marketing their use of explainable AI as a key feature and differentiator.[30] The move toward XAI is not just a technical enhancement but a necessary step for the responsible and ethical deployment of AI in talent acquisition.
5. Strategic Implementation and Best Practices
Successfully integrating vector embedding technology into recruitment workflows requires more than just technical proficiency; it demands a strategic approach that encompasses careful model selection, robust governance, a commitment to human oversight, and a clear framework for measuring success. In this section, we will provide actionable guidance for organizations, addressing critical decisions related to technology choices, the non-negotiable role of the human-in-the-loop, data privacy considerations, and how to define and measure the true return on investment.
5.1. Model Selection: Custom vs. Pre-trained Embeddings
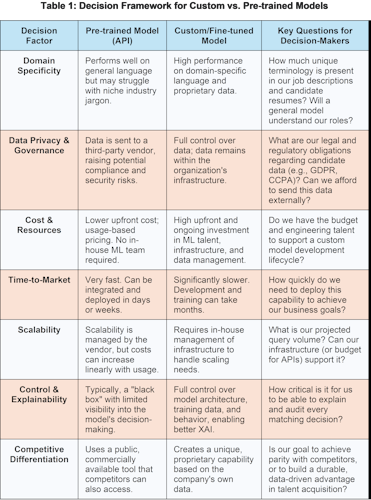
One of the most fundamental architectural decisions an organization will face is whether to use a commercially available, pre-trained embedding model via an API or to invest in building a custom model trained on its own data. This is not a binary choice, as a hybrid approach of fine-tuning a pre-trained model offers a compelling middle ground.
- Pre-trained Models (e.g., OpenAI, Cohere APIs): These are large, general-purpose models trained on vast swaths of public data and made accessible through an API.
🢣 Pros: This approach offers the fastest time-to-value, as it allows teams to quickly integrate powerful embedding capabilities without needing in-house ML expertise or infrastructure. It is often more cost-effective for low-to-medium volume use cases, as payment is typically usage-based. These models provide a high baseline performance on general language tasks.[41]
🢣 Cons: The primary drawback is a lack of control. These models often operate as "black boxes," making explainability and auditing difficult. They may underperform in highly specialized, domain-specific contexts that rely on jargon. Furthermore, sending sensitive candidate data to a third-party API raises significant concerns regarding data privacy and governance for many organizations, and it can lead to vendor lock-in.[42]
- Custom Models (Fine-tuned or Trained from Scratch): This involves either training an embedding model from scratch on a company's proprietary data or, more commonly, fine-tuning an existing open-source model.
🢣 Pros: Custom models deliver superior performance on domain-specific tasks because they are trained to understand the unique language and context of a specific industry or company. By embedding proprietary data and knowledge, an organization can create a true competitive differentiator that cannot be replicated with publicly available models. Crucially, this approach provides full control over data governance, security, and compliance, as all data and model artifacts remain in-house.[42]
🢣 Cons: The investment required is substantial. Building and maintaining custom models requires a team of skilled ML engineers, significant computational infrastructure (such as GPUs), and robust processes for data labeling, model versioning, and ongoing evaluation. The time-to-value is significantly longer than using a pre-built API.[41]
- The Hybrid Approach (Fine-tuning): For many organizations, the optimal solution is a hybrid approach: taking a powerful, open-source pre-trained model (such as a variant of SBERT from a repository like Hugging Face) and then fine-tuning it on a smaller, domain-specific dataset. This strategy offers an effective balance of performance, cost, and control. It inherits the powerful, general language understanding of the large base model while adapting it to the specific vocabulary and nuances of the target domain, such as recruitment.[59] This is often the most pragmatic path to achieving high performance without the prohibitive cost of training a large model from scratch.
To support this strategic decision, the following framework highlights the important trade-offs to consider.
Table 1: Decision Framework for Custom vs. Pre-trained Models
5.2. The Human-in-the-Loop (HITL) Imperative
Regardless of the model chosen, a core principle for responsible AI implementation in recruitment is that the technology must serve as a co-pilot, not an autopilot. The stakes are too high, and the nuances of human potential are too complex to be fully automated. Human judgment remains indispensable for assessing soft skills, evaluating cultural fit, navigating complex ethical situations, and ultimately retaining final decision-making authority.[48]
- Best Practices for HITL Implementation:
🢣 Define Automation Boundaries: Establish clear protocols for which tasks are fully automated, which are AI-assisted, and which are performed exclusively by humans. For example, AI can perform the initial parsing and ranking of all resumes; however, a human recruiter must review the AI-generated shortlist before any candidate contact is made, and a human must ultimately make the final hiring decision. [53]
🢣 Active Review at Critical Stages: Design the workflow with mandatory human checkpoints to ensure thorough review. A standard model is a hybrid decision pipeline where the AI performs an initial, broad filtering, and a human then reviews the AI's recommendations to validate its choices and, importantly, to rescue any qualified candidates the AI may have overlooked. [53]
🢣 Feedback Loops for Continuous Improvement: The HITL process is not just about oversight; it's about teaching and learning. The corrections, validations, and final decisions made by human recruiters should be captured and fed back into the system as new training data. This feedback loop enables the AI model to continually learn from human expertise and enhance its accuracy over time.[62]
🢣 Focus Humans on High-Value Tasks: The ultimate goal of automation is to free up human talent for work that requires uniquely human skills. By automating repetitive, low-nuance tasks such as scheduling, keyword screening, and initial data entry, recruiters can reallocate their time to strategic activities, including building deep relationships with top candidates, conducting nuanced interviews, advising hiring managers, and making holistic, context-aware judgments. [55]
5.3. Data Governance and Privacy
The use of AI in recruitment involves handling large volumes of sensitive personal data, making robust data governance and privacy practices essential.
- Compliance is Key: All systems must be designed from the ground up to comply with relevant data privacy regulations, such as the General Data Protection Regulation (GDPR) in Europe and the California Consumer Privacy Act (CCPA) in the United States.61
- Best Practices:
🢣 Transparency: Organizations must be transparent with candidates about the use of AI in the hiring process. This includes informing them about the data being collected and how it is used to make decisions.[51]
🢣 Data Security: All sensitive candidate data must be encrypted both in transit and at rest. Strict access controls should be implemented to ensure that only authorized personnel can view personal data, and all access should be logged.[61]
🢣 Data Minimization and Redaction: To reduce privacy risks and potential bias, organizations should practice data minimization, collecting only the data that is strictly necessary. AI tools can also be used to automatically redact personal information (such as names or addresses) from resumes before they are evaluated by the model or human reviewers.[61]
5.4. Measuring Success: The True ROI of AI in HR
Measuring the return on investment (ROI) for AI in HR is a complex process. While traditional efficiency metrics are essential, the actual value often lies in qualitative improvements and long-term strategic gains.
- Key Performance Indicators (KPIs):
🢣 Quantitative Metrics: These are the most direct measures of efficiency. They include reductions in time-to-fill and time-to-hire [27], increases in recruiter capacity and productivity [26], direct cost savings from reduced reliance on external agencies [31], and measurable improvements in workforce diversity metrics.[31] One survey of HR leaders reported a median ROI of 15% from their AI investments, with top performers achieving 55% or higher[63]
🢣 Qualitative Metrics: The true ROI extends beyond these numbers. It includes improvements in the quality of hire, as predicted by AI analytics; enhanced candidate satisfaction due to faster, more transparent processes [27]; and higher employee engagement and retention resulting from better internal mobility and development opportunities. Perhaps most importantly, it includes the strategic benefit of allowing the talent acquisition team to focus on more value-added, human-centric tasks.[64]
- A Long-Term Perspective: The ROI from AI is not immediate. It is a long-term journey that requires significant upfront investment in technology, process redesign, and training. HR leaders report that it can take three to five years to realize the benefits as the system is integrated fully, models are refined with feedback, and the organization adapts to the new workflows.[63]
Ultimately, the successful implementation of AI in recruitment is not just a technical project but a comprehensive change management initiative. It requires a holistic approach that aligns technology with redesigned processes, robust governance, and a well-trained team, all guided by a clear strategic vision.
6. The Future of Intelligent Talent Acquisition
The semantic revolution in recruitment is still in its early stages of development. The underlying technologies are evolving at a rapid pace, promising capabilities that will further transform how organizations find, evaluate, and manage talent. We look ahead in this final section, exploring the trajectory of embedding technology and its likely impact on the recruitment industry, culminating in a new model for the role of the human recruiter—one based on a symbiotic partnership between human and machine.

6.1. Emerging Trends in Embedding Technology
The current state-of-the-art is primarily focused on text-based semantic understanding. The next frontier lies in creating a more holistic and multifaceted representation of a candidate by integrating diverse data types.
- Multimodal Embeddings: The future of candidate assessment lies in moving beyond text alone. Emerging multimodal models, such as OpenAI's CLIP and Google Gemini (which aligns text and images), are paving the way for systems that can create a single, unified embedding vector representing a candidate from multiple data sources. Imagine a system that can semantically understand and compare a candidate's resume (text), their design portfolio (images), their code contributions on GitHub (code), and even their communication style from a pre-screening video interview (audio and speech patterns). This would enable a far richer and more holistic matching process, capable of, for example, matching a designer's visual aesthetic to a company's brand identity or a developer's coding style to a team's established best practices. This is the logical evolution beyond simple semantic text matching.[43]
- Multilingual and Cross-Lingual Models: As large language models continue to expand their linguistic capabilities, truly global, language-agnostic talent sourcing will become a reality. Models like Google's Gemini Embedding, which is trained on and supports hundreds of languages, will allow a recruiter to enter a query in English and seamlessly find the best-fit candidates regardless of whether their resumes are written in French, Japanese, or Hindi. These models operate in a shared embedding space, where the vectors for semantically similar concepts are close together, irrespective of the original language. This will break down language barriers and dramatically expand the global talent pool available to organizations.[43]
- Instruction-Tuned and Dynamic Embeddings: There is a significant trend toward instruction-tuned embedding models, like Google's E5 family. These models are trained not only on raw text but also on text paired with a natural language instruction that describes the task (e.g., "Instruct: Given a question, retrieve relevant passages…"). This makes them incredibly flexible. In a recruitment context, a recruiter could move beyond a simple job description query and use a more nuanced prompt, such as, "Find me software engineers with strong leadership skills who are likely to thrive in a fast-paced, early-stage startup culture." The model would then dynamically adjust its search parameters based on the intent captured in the instruction, providing a more targeted and context-aware set of results. This moves the interaction from a simple search to a more sophisticated, conversational dialogue with the talent database.[43]
6.2. The Future of the Recruiter: The Centaur Model
The rise of powerful AI does not signal the end of the human recruiter. Rather, it signals a fundamental evolution of the role. AI will continue to automate the high-volume, repetitive, and data-intensive tasks that have traditionally consumed the bulk of a recruiter's time: sourcing candidates from vast pools, conducting initial resume screening, scheduling interviews, and handling initial candidate communications.[33] This automation of tasks, however, does not equate to automating the job itself.
The most effective and sustainable model for the future is the "centaur" model—a hybrid that combines human intelligence and artificial intelligence in a powerful symbiosis.[64] In this model, the AI handles the scale, speed, and computational complexity of processing massive datasets. At the same time, humans provide the strategic direction, ethical oversight, empathy, and nuanced judgment that machines lack.
This shift will necessitate an evolution of the recruiter's skill set. The core competency of a future recruiter will no longer be their ability to craft complex Boolean search strings or manually sift through hundreds of resumes. Instead, their value will shift up the strategic stack. The recruiter of the future will be a "talent advisor" and an "AI operator," whose key skills will be:
- Strategic Profile Definition: The ability to deeply analyze a role's requirements and the characteristics of top performers to craft a high-fidelity Ideal Candidate Profile that can effectively guide the AI.
- Data Literacy and Critical Evaluation: The ability to interpret AI-generated insights, understand the system's confidence levels, identify potential biases in the output, and audit the AI's reasoning.
- Nuanced Human Assessment: A heightened focus on evaluating the qualities that AI cannot easily measure: deep-seated soft skills, cultural fit, motivation, ambition, and creative problem-solving ability.
- Advanced Relationship Management: With administrative tasks automated, the recruiter's primary function becomes building deep, meaningful relationships with top-tier candidates, acting as a trusted career advisor and brand ambassador.
- Strategic Decision-Making: Using AI-surfaced data and insights to make holistic, context-aware hiring decisions in partnership with business leaders.[55]
In conclusion, vector embedding technology is not merely an incremental improvement in recruitment tools; it is a foundational shift that is redefining the relationship between talent, data, and opportunity. While the path to implementation is fraught with technical and ethical challenges, organizations that successfully navigate it will not only achieve greater efficiency but also unlock a more strategic, data-driven, and ultimately more human approach to building their teams. The future of talent acquisition belongs to the centaurs—the human experts who learn to wield these powerful AI tools with wisdom, judgment, and strategic intent.
References and further reading
- How to use semantic search to expand your candidate pool, accessed June 29, 2025, https://resources.careerbuilder.com/recruiting-solutions/how-to-use-semantic-search-to-expand-your-candidate-pool
- Semantic Search in Recruitment: The Winning Edge - Talentprise, accessed June 29, 2025, https://www.talentprise.com/ai-powered-semantic-search-in-recruitment/
- Semantic research: a guide for recruiters and HR - Inda, accessed June 29, 2025, https://inda.ai/en/semantic-research-a-guide-for-recruiters-and-hr/
- Unleashing the Power of Vector Search in Recruitment Bridging ..., accessed June 29, 2025, https://recruitmentsmart.com/blogs/unleashing-the-power-of-vector-search-in-recruitment-bridging-talent-and-opportunity-through-advanced-technology
- Semantic Search in Recruitment: From Filters to Context - HeroHunt.ai, accessed June 29, 2025, https://www.herohunt.ai/blog/semantic-search-in-recruitment
- How Semantic Search is Being Used in AI Recruitment - CVViZ, accessed June 29, 2025, https://cvviz.com/blog/how-semantic-search-used-in-recruitment/
- AI in Recruitment: How Vector Search is Transforming Talent Acquisition Strategies, accessed June 29, 2025, https://opportunitydesk.org/2025/02/07/ai-in-recruitment-how-vector-search-is-transforming-talent-acquisition-strategies/
- Search & Match Engine-AI Matching Matches jobs to ideal candidates, accessed June 29, 2025, https://www.rchilli.com/solutions/semantic-search
- SEO Use Cases for Vectorizing the Web with Screaming Frog, accessed June 29, 2025, https://ipullrank.com/vector-embeddings-is-all-you-need
- AI foundations: Understanding embeddings - Labelbox, accessed June 29, 2025, https://labelbox.com/guides/ai-foundations-understanding-embeddings/
- Vector Retrieval for Real-Time Embedding Lookup | by Bijit Ghosh ..., accessed June 29, 2025, https://medium.com/@bijit211987/vector-retrieval-for-real-time-embedding-lookup-128591705968
- Applying BERT-Based NLP for Automated Resume Screening and ..., accessed June 29, 2025, https://www.researchgate.net/publication/378829570_Applying_BERT-Based_NLP_for_Automated_Resume_Screening_and_Candidate_Ranking
- DeepMatch: A BERT-Powered Talent Matchmaking Approach, accessed June 29, 2025, https://www.researchgate.net/publication/389497054_DeepMatch_A_BERT-Powered_Talent_Matchmaking_Approach
- Resume2Vec: Transforming Applicant Tracking Systems with ... - MDPI, accessed June 29, 2025, https://www.mdpi.com/2079-9292/14/4/794
- What Are Vector Embeddings: Types, Use Cases, & Models | Airbyte, accessed June 29, 2025, https://airbyte.com/data-engineering-resources/vector-embeddings
- Vector relevance and ranking - Azure AI Search | Microsoft Learn, accessed June 29, 2025, https://learn.microsoft.com/en-us/azure/search/vector-search-ranking
- BERTScore in AI: Enhancing Text Evaluation - Galileo AI, accessed June 29, 2025, https://galileo.ai/blog/bert-score-explained-guide
- Talent Matching with Vector Embeddings - ingedata, accessed June 29, 2025, https://www.ingedata.ai/blog/2025/04/01/talent-matching-with-vector-embeddings/
- Candidate Sourcing with Semantic Search for Top Talent - Talentprise, accessed June 29, 2025, https://www.talentprise.com/how-candidate-sourcing-work-for-recruiters/
- AI Candidate Matching: A Complete Guide - Recruiterflow Blog, accessed June 29, 2025, https://recruiterflow.com/blog/candidate-matching/
- Which applicant tracking system uses AI for identifying the best talent? - Quora, accessed June 29, 2025, https://www.quora.com/Which-applicant-tracking-system-uses-AI-for-identifying-the-best-talent
- Ideal Candidate Profile: How to Create One with AI [Example ... - Carv, accessed June 29, 2025, https://www.carv.com/blog/create-ideal-candidate-profile
- How to Find Candidates Using AI: 2024 Guide - HeroHunt.ai, accessed June 29, 2025, https://www.herohunt.ai/blog/how-to-find-candidates-using-ai
- How to Create Post-interview Candidate Profiles in Seconds With AI ..., accessed June 29, 2025, https://www.carv.com/blog/how-to-create-candidate-profiles-with-ai
- AI In Recruitment: A Beginner's Guide To Ensuring Hiring Efficiency, accessed June 29, 2025, https://vervoe.com/ai-recruiting-101-a-beginners-guide-to-improving-your-hiring-process/
- AI For Recruiting | Workday US, accessed June 29, 2025, https://www.workday.com/en-us/products/talent-management/ai-recruiting.html
- Best AI Solutions for Automated Candidate Screening - MokaHR, accessed June 29, 2025, https://www.mokahr.io/myblog/ai-automated-candidate-screening-best-tools-for-recruiters/
- Which ATS allows the following search: upload JD and ask for list of best 10 candidates : r/recruiting - Reddit, accessed June 29, 2025, https://www.reddit.com/r/recruiting/comments/1j451mw/which_ats_allows_the_following_search_upload_jd/
- An ATS that doesn't need keywords : r/recruiting - Reddit, accessed June 29, 2025, https://www.reddit.com/r/recruiting/comments/16pnf8g/an_ats_that_doesnt_need_keywords/
- Top 10 AI Recruitment Tools to Streamline Hiring | Findem, accessed June 29, 2025, https://www.findem.ai/knowledge-center/ai-recruitment-tools
- Practical AI Use Cases with ROI: Real-World Insights - Leanware, accessed June 29, 2025, https://www.leanware.co/insights/ai-use-cases-with-roi
- Top 12 AI Recruiting Software and Screening Tools for Hiring Top ..., accessed June 29, 2025, https://arc.dev/employer-blog/ai-screening-tools-and-recruiting-software/
- The Ultimate 2025 AI Recruiting Guide: Save Time, Hire Smarter ..., accessed June 29, 2025, https://www.phenom.com/blog/recruiting-ai-guide
- AI Tools for Role-Specific Candidate Scoring - JobSwift.AI, accessed June 29, 2025, https://jobswift.ai/blog/ai-tools-for-role-specific-candidate-scoring/
- SEMANTIC SEARCH | eBoss Recruitment Software, accessed June 29, 2025, https://www.ebossrecruitment.com/features/semantic-search/
- Interviewer.AI | #1 End-to-End AI Video Interview Platform, accessed June 29, 2025, https://interviewer.ai/
- The Future of Talent Acquisition Trends: How AI is Reshaping ..., accessed June 29, 2025, https://sciontechnical.com/future-talent-acquisition-trends-how-ai-reshaping-recruiting/
- The Future of Recruitment: How AI Is Transforming Talent Acquisition | Talando, accessed June 29, 2025, https://talando.com/blog/the-future-of-recruitment-how-ai-is-transforming-talent-acquisition/
- What are the challenges of working with vector embeddings? - Milvus, accessed June 29, 2025, https://milvus.io/ai-quick-reference/what-are-the-challenges-of-working-with-vector-embeddings
- What Are Embedding Models? Benefits and Best Practices - Cohere, accessed June 29, 2025, https://cohere.com/blog/embedding-models
- Custom AI Models VS Pre-trained Models: Make the Best Choice, accessed June 29, 2025, https://oyelabs.com/custom-ai-models-vs-pre-trained-models/
- Custom Embedding Models vs Pre-Trained Models - AI at work for ..., accessed June 29, 2025, https://shieldbase.ai/blog/custom-embedding-models-vs-pre-trained-models
- The State of Embedding Technologies for Large Language Models ..., accessed June 29, 2025, https://medium.com/@adnanmasood/the-state-of-embedding-technologies-for-large-language-models-trends-taxonomies-benchmarks-and-95e5ec303f67
- How To Demonstrate Soft Skills on Your Resume, accessed June 29, 2025, https://resumeworded.com/soft-skills-on-resume-key-advice
- What's a good way to mention your soft skills in your resume? : r ..., accessed June 29, 2025, https://www.reddit.com/r/resumes/comments/1klynv4/whats_a_good_way_to_mention_your_soft_skills_in/
- Fairness in AI-Driven Recruitment: Challenges, Metrics, Methods, and Future Directions, accessed June 29, 2025, https://arxiv.org/html/2405.19699v3
- Algorithmic Fairness In Hiring → Term, accessed June 29, 2025, https://pollution.sustainability-directory.com/term/algorithmic-fairness-in-hiring/
- 3 Ways to Neutralize AI Bias in Recruiting | Visier, accessed June 29, 2025, https://www.visier.com/blog/neutralize-ai-bias-in-recruiting/
- AI overwhelmingly prefers white and male job candidates in new test ..., accessed June 29, 2025, https://www.geekwire.com/2024/ai-overwhelmingly-prefers-white-and-male-job-candidates-in-new-test-of-resume-screening-bias/
- Fairness and Bias in Algorithmic Hiring | Montreal AI Ethics Institute, accessed June 29, 2025, https://montrealethics.ai/fairness-and-bias-in-algorithmic-hiring/
- Understanding Algorithmic Bias to Improve Talent Acquisition ..., accessed June 29, 2025, https://info.recruitics.com/blog/understanding-algorithmic-bias-to-improve-talent-acquisition-outcomes
- Algorithmic Bias in Job Hiring - Gender Policy Report, accessed June 29, 2025, https://genderpolicyreport.umn.edu/algorithmic-bias-in-job-hiring/
- Human-in-the-Loop: Keeping recruiters in control of AI-Driven ..., accessed June 29, 2025, https://www.sourcegeek.com/en/news/human-in-the-loop-keeping-recruiters-in-control-of-ai-driven-recruitment
- Leveraging Explainable AI (XAI) for Talent Management and ..., accessed June 29, 2025, https://www.researchgate.net/publication/391381334_Leveraging_Explainable_AI_XAI_for_Talent_Management_and_Employer_Branding_in_the_Digital_Era
- How AI Is Changing Recruitment In 2025 | MSH, accessed June 29, 2025, https://www.talentmsh.com/insights/ai-in-recruitment
- AI and the Hiring Revolution: Rethinking Access and Equality in a ..., accessed June 29, 2025, https://directemployers.org/2025/05/29/ai-and-the-hiring-revolution-rethinking-access-and-equality-in-a-tech-driven-world/
- How Explainable AI Enhances Transparency In Recruitment ..., accessed June 29, 2025, https://www.talentrx.ai/blog/how-explainable-ai-enhances-transparency-in-recruitment-decisions
- arxiv.org, accessed June 29, 2025, https://arxiv.org/html/2504.02870v1
- Pre-trained and Custom models: when to use which? | VectorHub by ..., accessed June 29, 2025, https://superlinked.com/vectorhub/building-blocks/vector-compute/pre-train-custom-models
- www.vonage.com, accessed June 29, 2025, https://www.vonage.com/resources/articles/ai-for-recruiting/#:~:text=Use%20AI%20for%20repetitive%2C%20data,is%20both%20effective%20and%20efficient.
- HR Best Practices for the Age of AI - How to Succeed in 2025, accessed June 29, 2025, https://www.centuroglobal.com/article/hr-best-practices-ai/
- The Complete Guide to Human-in-the-Loop Automation - Klippa, accessed June 29, 2025, https://www.klippa.com/en/blog/information/human-in-the-loop/
- The return on investment of AI in HR: It's time for a ... - HR Executive, accessed June 29, 2025, https://hrexecutive.com/whats-the-roi-of-ai-in-hr/
- realizing the true ROI of AI investments | Randstad Advisory, accessed June 29, 2025, https://www.randstadenterprise.com/insights/randstad-enterprise-insights/beyond-dollars-and-cents-realizing-the-true-roi-of-ai-investments/



